
I remember it clearly, it was 2 o’clock in the morning back in the ancient year of 2000. I was working for a .com loading an Oracle data warehouse sitting on a single Sun Microsystems server. If one thing went wrong, it would delay the nightly load and cost four hours of rollback. There was no such thing as elasticity or a public cloud.
Fast forward almost 20 years. While the need for loading, moving, and analyzing data continues, tremendous advances abound in hardware, networking, and the commoditization of infrastructure started by Amazon’s AWS (VMware also deserves credit for this as well). One of the single most important advances is the separation of storage and compute driven by low cost object stores such as S3 by AWS. Companies can finally take control and complete ownership of their data using open storage formats such as Parquet and ORC. Together, these advances let us process data at a fraction of previous times, and with a variety of tools. We can at last free ourselves…
Trino and Spark: Open Analytics Platform
The diagram below illustrates the flexibility of an open data store. Using different processing tools, users and departments from multiple locations can add, remove, update and select data without limited storage or bandwidth restrictions. We’re no longer locked into a vendor-controlled ecosystem.
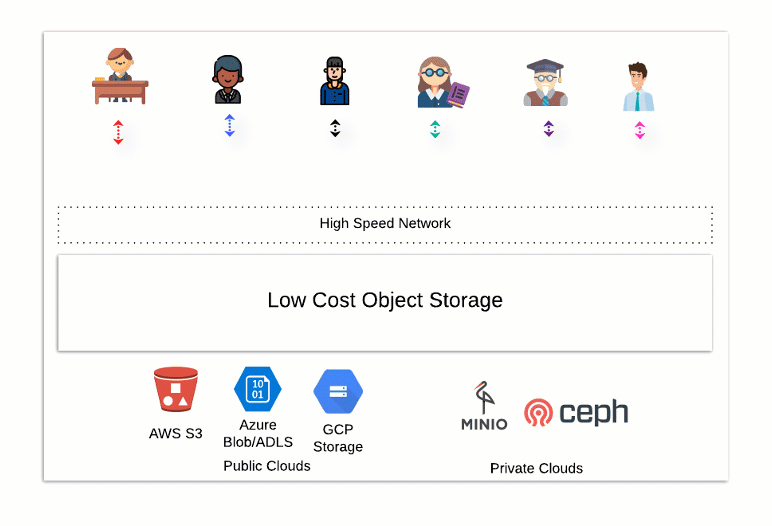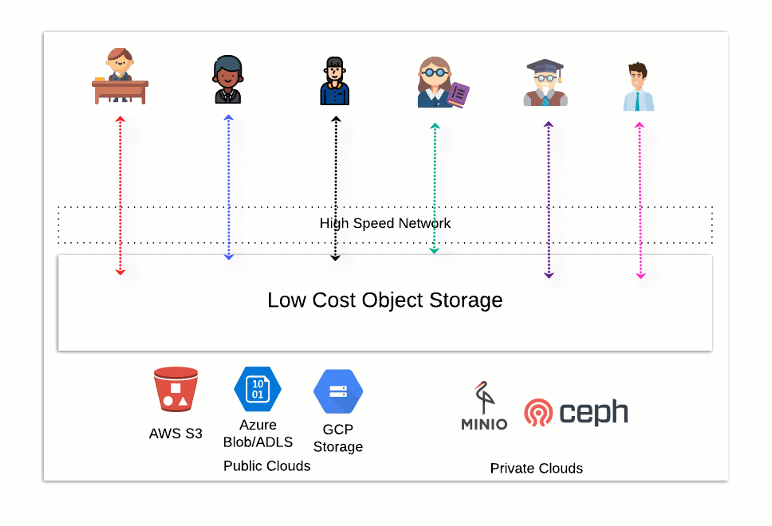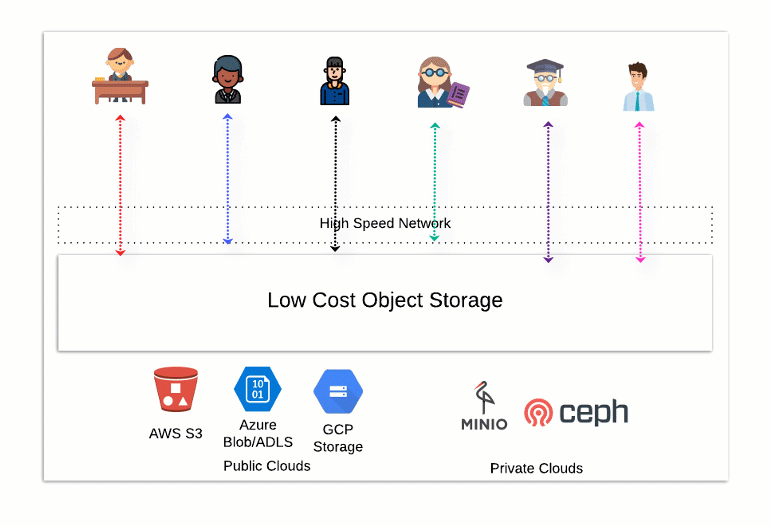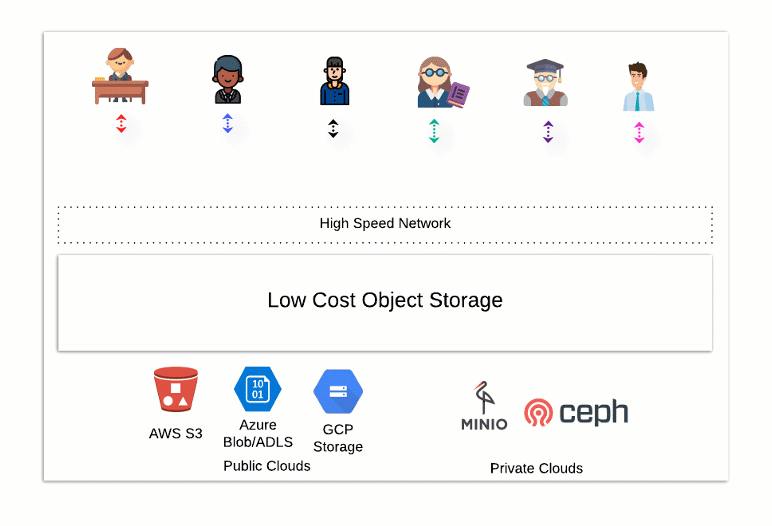
What does an open data, analytical ecosystem look like? Here at Starburst, we believe this architecture combines open source technology with enterprise features and security. It all begins with a distributed storage system such as AWS’ S3. The separate storage layer is located within your control and account. You can access your data with different compute technologies, freeing you from data lock-in.
Two specific technologies created within the last 5 years take advantage of this separation of storage and compute. They are Spark and Trino (formerly PrestoSQL). Spark was created out of Berkley’s AMP lab and is like a Swiss army knife as it can handle tasks such as ingestion, ETL (Extract Transform & Load) and machine learning. Trino was created from the folks over at Facebook and provides a highly concurrent SQL engine that can query large amounts of data against a variety of data platforms.
Together, these two technologies make up something we called the true unified, Open Analytics Platform. In a typical analytical environment, you ingest data, process it and make it available to users. Using both Trino and Spark together can handle these tasks with ease and work on a variety of platforms. The simple diagram below illustrates how both technologies work together to ingest, catalog, process, enrich and analyze different types and volumes of data.
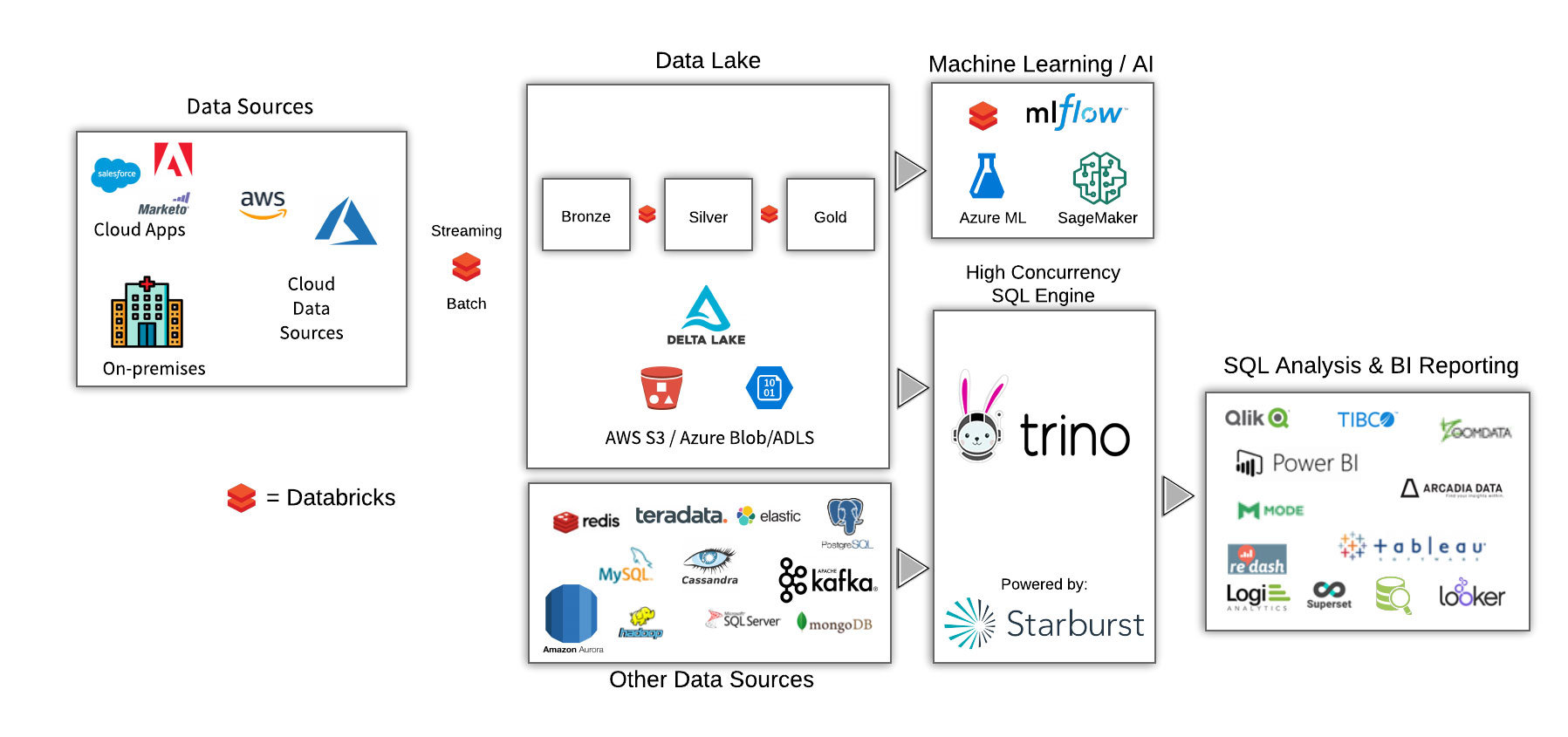
We can break down these traditional tasks:
Data ingestion
Using Databrick’s Spark-based platform makes ingestion a breeze using batch or structured streaming.
Data lake management
Data lakes can quickly turn into ugly data swamps without strict governance and tools that allow for seamless management. Using Databricks and their open-sourced Delta Lake finally gives companies a method to build clean data lakes.
Machine & Deep learning
Spark and machine learning are usually found in the same sentence so it’s no surprise that a majority of companies are using it to take advantage of expanding their ML use cases using Databricks.
SQL query engine
Trino provides a massively parallel SQL engine that can join data from many different systems at scale on any cloud and on-premises. Use cases revolve around adhoc data analysis to high concurrent BI reporting. Starburst adds in enterprise features such as fine-grained access control, certified ODBC/JDBC drivers, enterprise tested connectors such as Oracle and 24/7 support by actual Trino committers.
Databricks and Starburst: Modern, open analytical platform
As companies migrate their on-premises systems to the cloud, they want to avoid any mistakes made in the past. They want low-cost storage separated from compute in their own account, complete ownership of their data using open formats such as Parquet/ORC and the ability to scale up and down based on their requirements.
The combination of Databricks and Starburst meet all current requirements for a modern, open analytical platform, helping companies future-proof their investments for whatever lies ahead.




