

A data lakehouse combines the principles of a data lake and a data warehouse to include the best of both worlds. Data lakehouses are built on object storage and follow the separation of storage and compute principle, which provides flexibility that was previously unthinkable. By leveraging open table formats to apply data warehouse functionality to a data lake, it is now possible to build a performant reporting structure on low cost cloud object storage and prevent the dreaded data swamp that many data lakes have turned into today.
Identifying when to adopt a data lakehouse becomes much easier when you can recognize constraints you have encountered or may potentially encounter within your own data ecosystem. The image below outlines several challenges with traditional data warehouse and data lake architecture that may indicate it’s time to adopt a data lakehouse architecture.
When to Adopt a Data Lakehouse
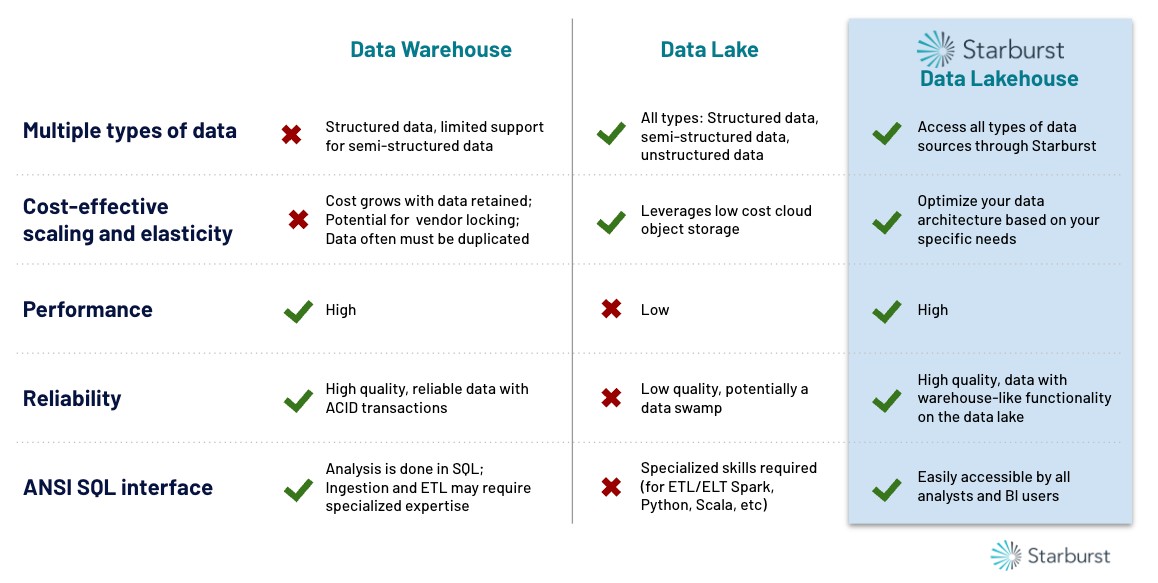
Normally, data warehouses are not cost friendly to organizations that desire to store multiple petabytes of data in all data formats. This architecture also struggles with scalability and can easily cause organizations to fall victim to vendor lock-in. If you are noticing either of these constraints, it may benefit you to adopt a data lakehouse and utilize the low cost cloud storage, which can store all types of data and scale appropriately.
If you’re already landing data into your data lake, but aren’t seeing the performance and reliability you expect, it may be beneficial to adopt a data lakehouse, or modern data lake. A data lakehouse allows you to leverage the data warehouse like functionality, which includes performance, reliability, and ease-of-use along with the functionality of a data lake, low cost storage.
Components of a Starburst Data Lakehouse
There are multiple components which contribute to you getting the most value out of your data lakehouse. The components highlighted are: Optionality, Flexibility, Open Table Formats, Performance and Scalability, and Native Security.
Incorporating optionality into your data ecosystem
![]()
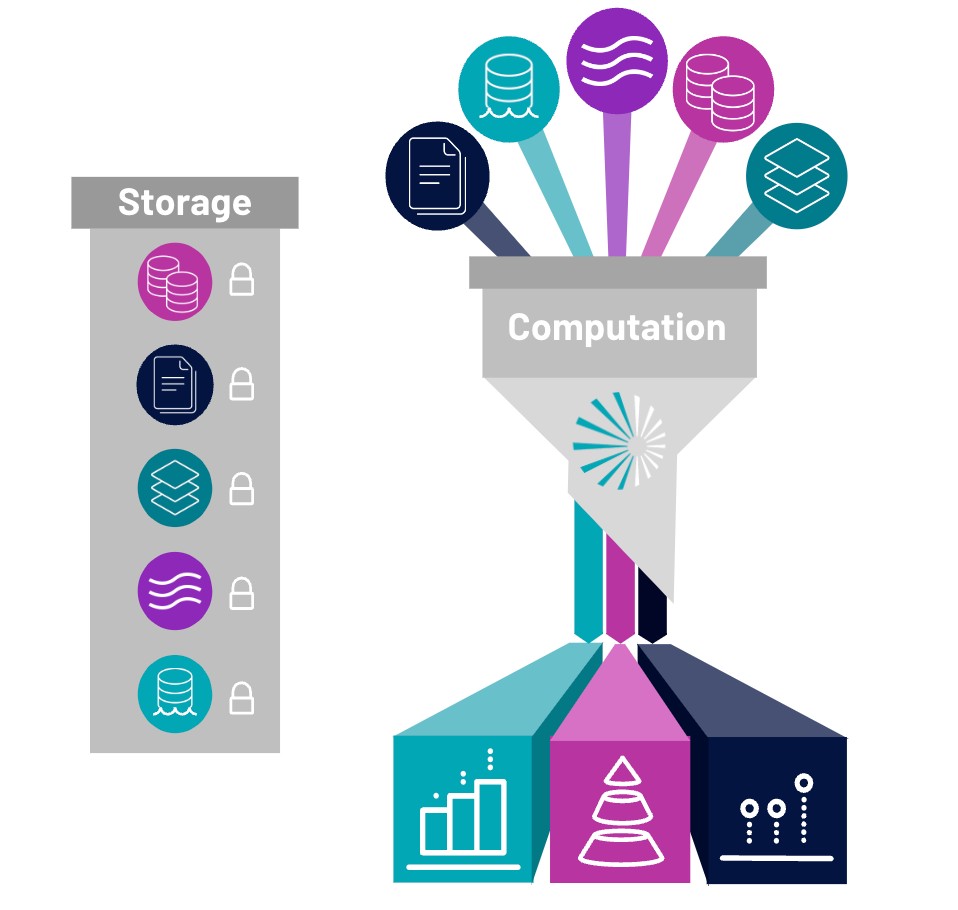
At Starburst, we believe that you should incorporate optionality into your data ecosystem in order to future-proof your architecture for any new technologies or data innovations that arise. The post modern data stack is growing, and companies may want to incorporate new tools into their data stack within the next few years. By embracing the separation of storage and compute with your data, you are able to not only prevent vendor lock in, but also remain agnostic in your cloud storage, table format, and even your data sources. When you build your data lakehouse with Starburst, you can rest assured that you’re able to integrate multiple table formats and connect to different clouds to fit your needs.
Enable flexibility by specifying the cost and performance efficiency
The Starburst Data lakehouse also incorporates flexibility by allowing you to specify the cost and performance efficiency that fits your needs. Enabling cluster autoscaling lets you scale up and down your compute sources automatically to meet the demands of your actively running queries. Starburst Galaxy also lets you run both interactive and long-running queries, while utilizing ANSI SQL for any data transformations. An effective data lakehouse engine must also be able to connect to and query multiple modern and legacy enterprise sources. Starburst’s extensive ecosystem of connectivity allows users to only pay for what they use and minimize data duplication.
Connect to multiple open table formats
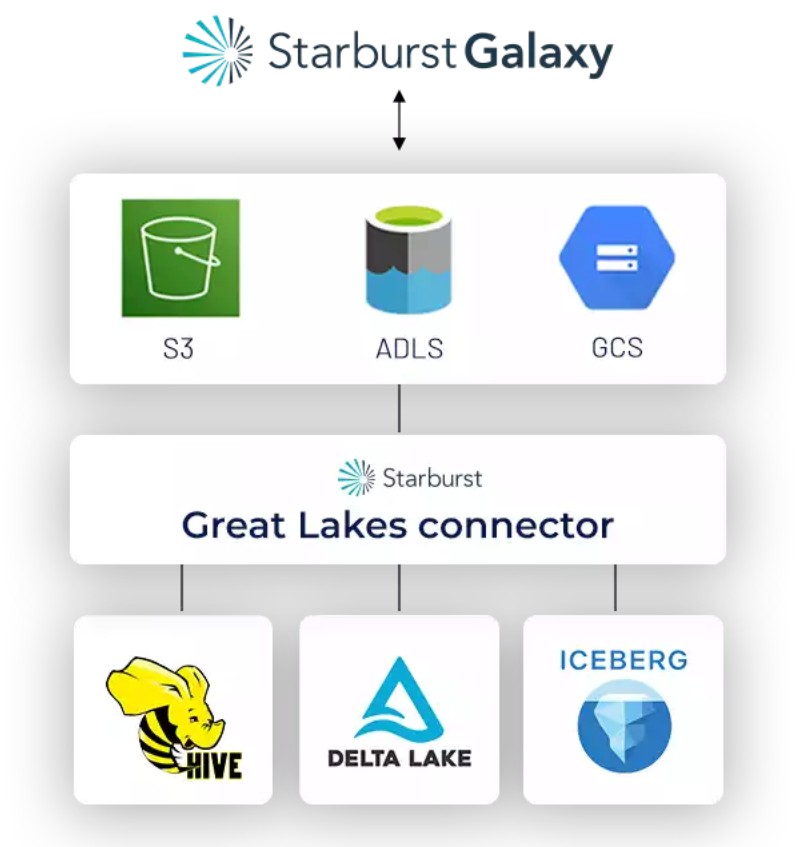
Query open table formats like Iceberg & Delta Lake
Continuing the theme of autonomy, the Starburst Data Lakehouse has enabled Starburst Galaxy to connect to multiple different open table formats such as Hive, Delta Lake, and Apache Iceberg. All you have to do is pick your format of choice when you are configuring your object storage catalog and Starburst Galaxy manages the rest behind the scenes for you so you don’t have to. This lets you leverage the power of these open table formats to achieve faster performance and add additional benefits such as schema evolution, time travel, and more. You can work with different formats seamlessly, allowing you to instantly leverage data warehouse-like functionality within your lakehouse.
Performance and Scalability: Accommodate your workloads and meet demand
With connections to multiple on premise and cloud based storage locations and a highly performant query engine built at scale, Starburst Galaxy is the best engine to power your data lakehouse. Starburst Galaxy is built on Trino, which is designed to query data at a petabyte scale and high concurrency and has multiple cost based optimizations built in to make the engine as efficient as possible.
You can easily and automatically scale up and down your clusters to accommodate your workloads and meet demand. This scalability component allows you to reduce your infrastructure cost required to hit your target user experience and scale your compute power only required during the peak hours.
Incorporate native security to ensure data governance and compliance
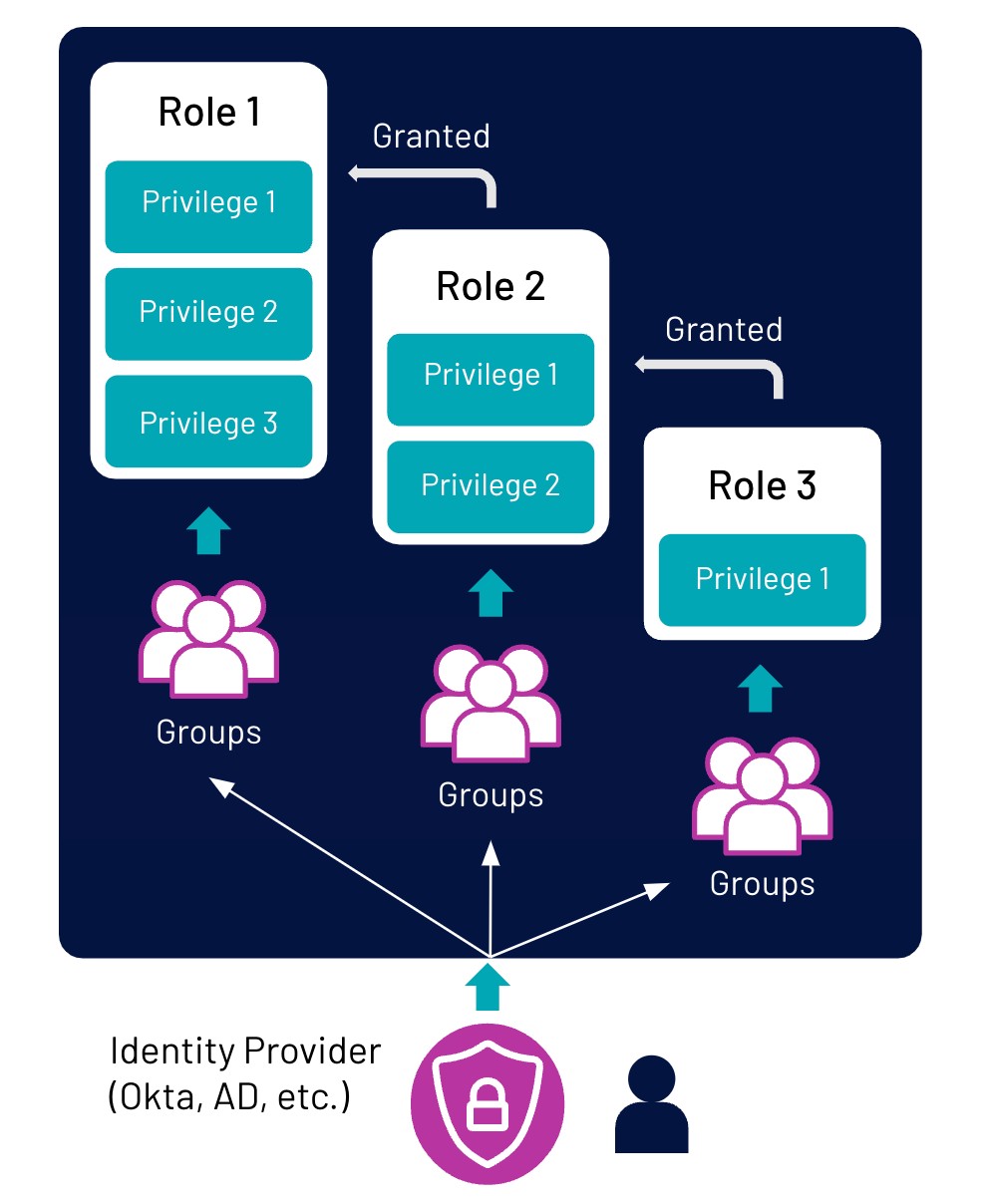
Your lakehouse must also incorporate native security in order to ensure data governance and compliance. Starburst galaxy has now integrated storage location based privileges so that you can specifically assign privileges to a specific object storage location. Starburst Galaxy also lets you assign role based access control down to the table level. As an administrator, you can completely customize access for multiple roles, allowing you to assign the proper privileges to different groups of users.
You can configure your SSO identity provider to include Starburst Galaxy as a supported application – which is currently supported by Okta, Azure AD, and Google Workspace.
How to build your Starburst Lakehouse

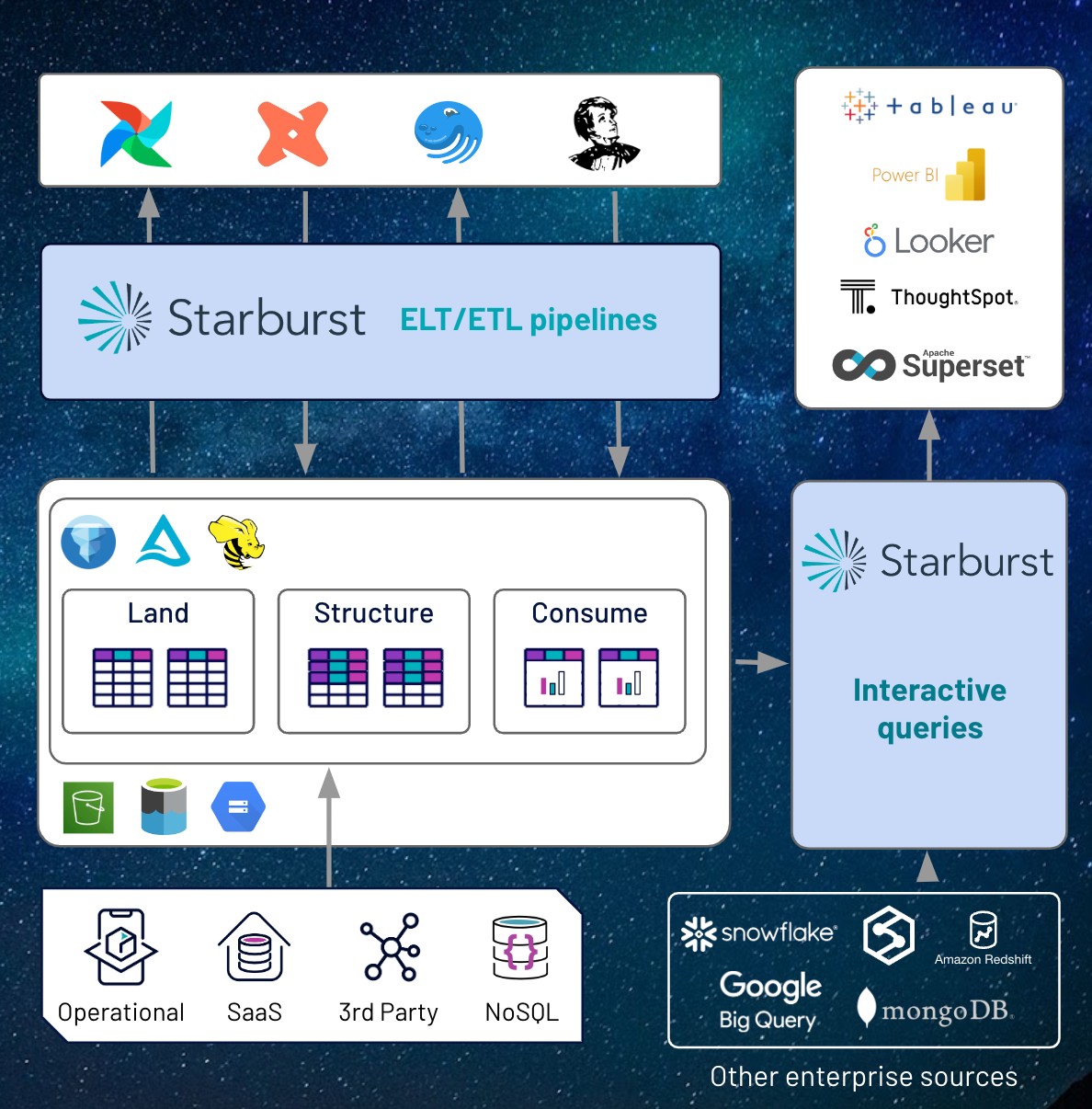
Now that we’ve discussed the “What”, let’s dive into the “How” and discuss how to build your Starburst Data Lakehouse. There are three layers within a data lakehouse reporting structure with each layer serving a different purpose. You may have heard synonyms for each layer before, as each can go by many names, but the purpose of each layer remains the same regardless of the naming convention.
1. Land
The land layer is used to land raw data and store any unmodified data from any source of any granularity.
2. Structure
The structure layer is used for joining, enriching, and cleansing data.
3. Consume
The consume layer holds aggregated data that is ready to be queried.
Starburst Enables the Data Lakehouse
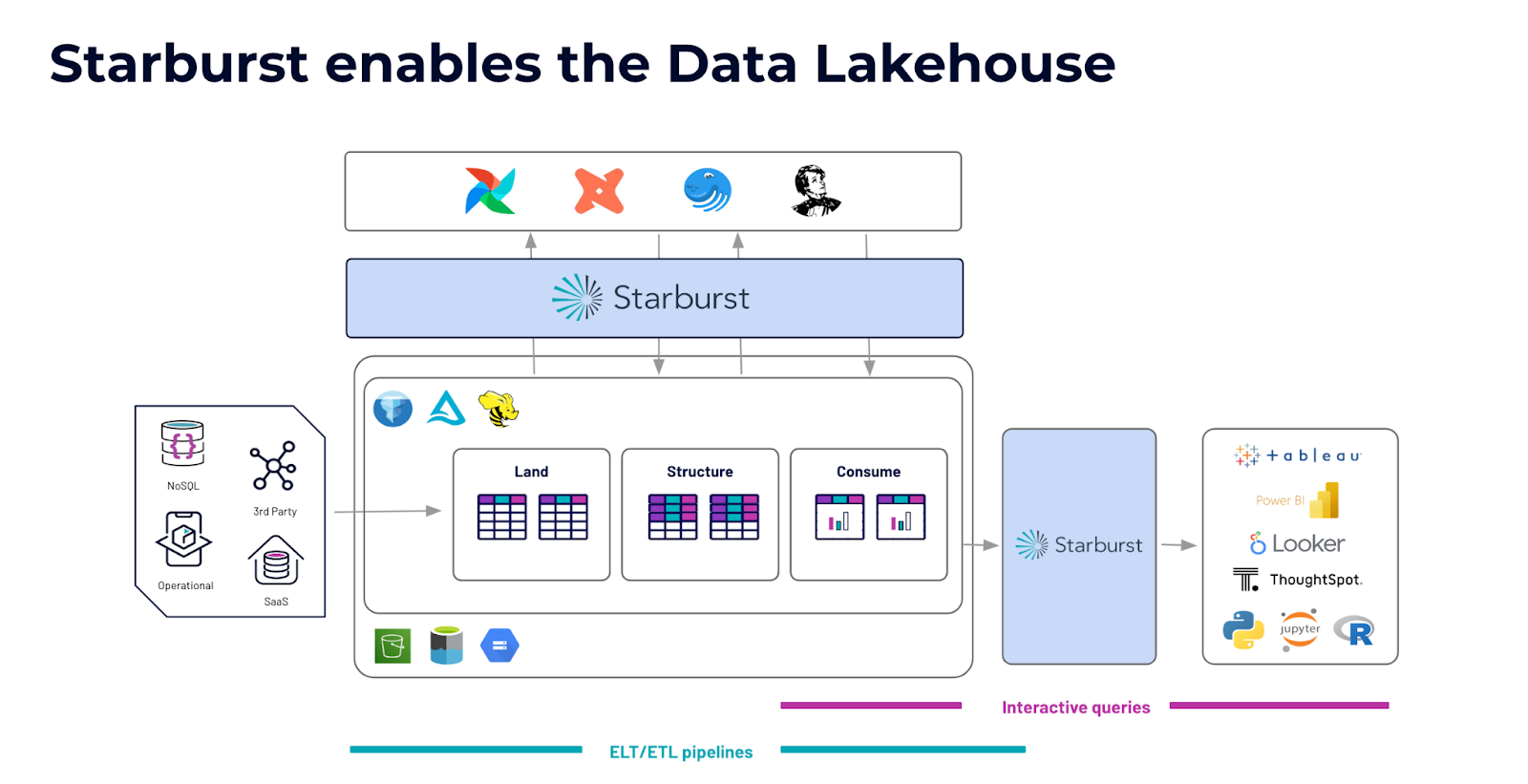
To create the data lakehouse, take the reporting structure and implement it within your storage location of your choice. Start by gathering data from your external sources and then landing that data in the land layer. From there, use Starburst Galaxy to clean your data using ANSI SQL and apply your open table format of choice to create your structure layer. Then construct your consume layer and create tables that are ready to be queried by your data consumers. To ensure proper data quality, you may choose to implement role-based access control on the consume tables to ensure data consumers only have read only privileges.
To create a robust pipeline, Starburst Galaxy also integrates with tools such as Great Expectations, dbt, Airflow, and Dagster. You will also have the ability to query interactively. Connect your consume tables to your BI tool of choice and set up your analysts to have read-only access to those consume tables to create dashboards or reports.
Optimizing your data lakehouse: the best of a data warehouse and data lake
As the needs for the data world have evolved, so have the tools available to ingest and view data. If you’ve been finding that there have been constraints in your own data architecture, it may be time to explore a new way of utilizing a data lakehouse, the best of both a data warehouse and a data lake.
Watch the full webinar, including a demo of Starburst Galaxy, on demand.
Try Starburst Galaxy for free
with up to $500 in usage credits today!




