
As a data enthusiast, one of my goals is to understand how organizations attempt to create a trusted and accurate single source of truth for their data. This goal of making all data accessible in one location for the business to make informed, timely, and intelligent decisions is often not as easy as we hope.
There’s a notorious problem with this admirable goal: moving all the data into one location tends to be costly and time-consuming.
By moving analytics closer to where the data lives, the time from raw data to actionable insights can be dramatically improved. Distributed query engines can access data where it is stored, and transform and join data from multiple sources like the data lake and data warehouse. One downside to many distributed engines is self-managing the infrastructure. Recently, some serverless and fully managed solutions are gaining traction in this space.
Amazon Athena is a serverless query service provided by AWS
With the service, query performance tends to be a bottleneck. The time used to troubleshoot and tune queries to solve for performance issues only amplified this bottleneck.
Athena was originally based on a fork of PrestoDB released in 2019 (version 0.217). Recently, Amazon announced it has upgraded Athena to a new engine based on a combination of open source Trino and Presto. Because of the way it is architected as a combination of the two open source projects, it will always be several releases behind the latest version of both open source projects.
Challenges with Athena
Athena includes data federation capabilities provided by the Presto and Trino engines. However, setting up connectors to new data sources is a multi-step process that involves the creation of Lambda functions and additional technical expertise.
Athena is designed to be a simplified managed service for data engineers seeking a quick way to query data. Athena’s pricing model is based on the amount of data scanned, which has the potential to become very expensive as your business scales and the amount of data queried grows.
As a managed service, Athena can appear to be a black box in terms of performance and cost. When you submit queries to the service, they may fail without explanation, or perhaps return with a vague “out-of-memory” error. It’s a great, simplified service for quickly querying your data in the AWS ecosystem. As such there’s no management of clusters or the compute behind each query but this simplicity also means there’s no ability to manage for your preferred cost/performance ratio.
As a “serverless” service, Athena’s compute resources are shared across its entire user base. Queued queries and slow performance at peak usage hours are a common consequence of the “noisy neighbor” problem.
AWS Athena alternative: Starburst Galaxy
Starburst Galaxy is a fully managed offering built on open-source Trino. It is always up to date with the latest version of the open-source project, allowing users to take advantage of new functionality, performance enhancements, bug fixes, and security patches. Starburst Galaxy dramatically simplifies Trino deployment with an intuitive user experience designed to get you started querying your data in less than five minutes.
It is available on all major clouds (AWS, Azure, and GCP) and provides connectors to the most popular data lakes, cloud data warehouses, RDBMS, and other data sources. Connectors are pre-configured; set-up is as simple as choosing your data source and entering your access credentials.
With Starburst Galaxy, you can manage the compute behind your queries by changing your cluster size, autoscaling helps manage costs during times of lower or higher than expected load, and idle shutdown automatically shuts down a cluster when not in use. This enables customers to get the best of both high query performance when it’s needed and lower idle costs. In addition, cluster scheduling will allow you to configure a cluster to run exactly when you need it when it lands in Starburst Galaxy in the next few weeks.
Additionally, resource-intensive clusters allow queries to run without hitting “out-of-memory” errors common in other query services. These clusters include query-level and task-level retries. This feature enables a cluster to pick back up where it left off in case there was such an error. This increases reliability in query performance, ensuring your workload’s success.
Finally, Starburst Galaxy was built by the founders and creators of the original Presto project as well as open-source Trino with 24×7 support from the largest team of Trino experts in the world. Starburst Galaxy, a fully-managed offering of open source Trino.
Migrate queries from AWS Athena to Starburst Galaxy: It’s easy!
First, simply sign-up for Starburst Galaxy at Starburst.io/Galaxy and activate the account. You can leverage the Get Started with Starburst Galaxy document as a handy guide. Starburst Galaxy makes it very easy to query data with 4 steps:

For this guide, I’ve chosen Amazon S3 as my data catalog to demonstrate query migration from Athena to Starburst Galaxy.
Starburst Galaxy takes advantage of using the same AWS Glue metastore that Athena is using. If you are not using Glue, Starburst Galaxy also provides a Hive Metastore Service and built-in metastore for your convenience. You do not need to configure and manage a separate Glue or Hive Metastore Service deployment or equivalent system.
Setting up permission using the AWS Cross account IAM role is a very easy process in Starburst Galaxy. Simply configure access using a cross-account IAM role or Access security with AWS access and a secret key for Glue to the AWS Glue region. Starburst Galaxy also has options to create and write to external tables of query results, allowing you to be able to create new sets of data to be shared and consumed by multiple users.
Step 1: Create an Amazon S3 Catalog

After creating a catalog, Starburst Galaxy now has access to the data source and can be used by clusters to query the data directly. Additionally, multiple catalogs can be added to a cluster, and you can query multiple catalogs in one SQL statement. This allows you to run federated queries against multiple data sources (i.e., your data lake and cloud data warehouse).

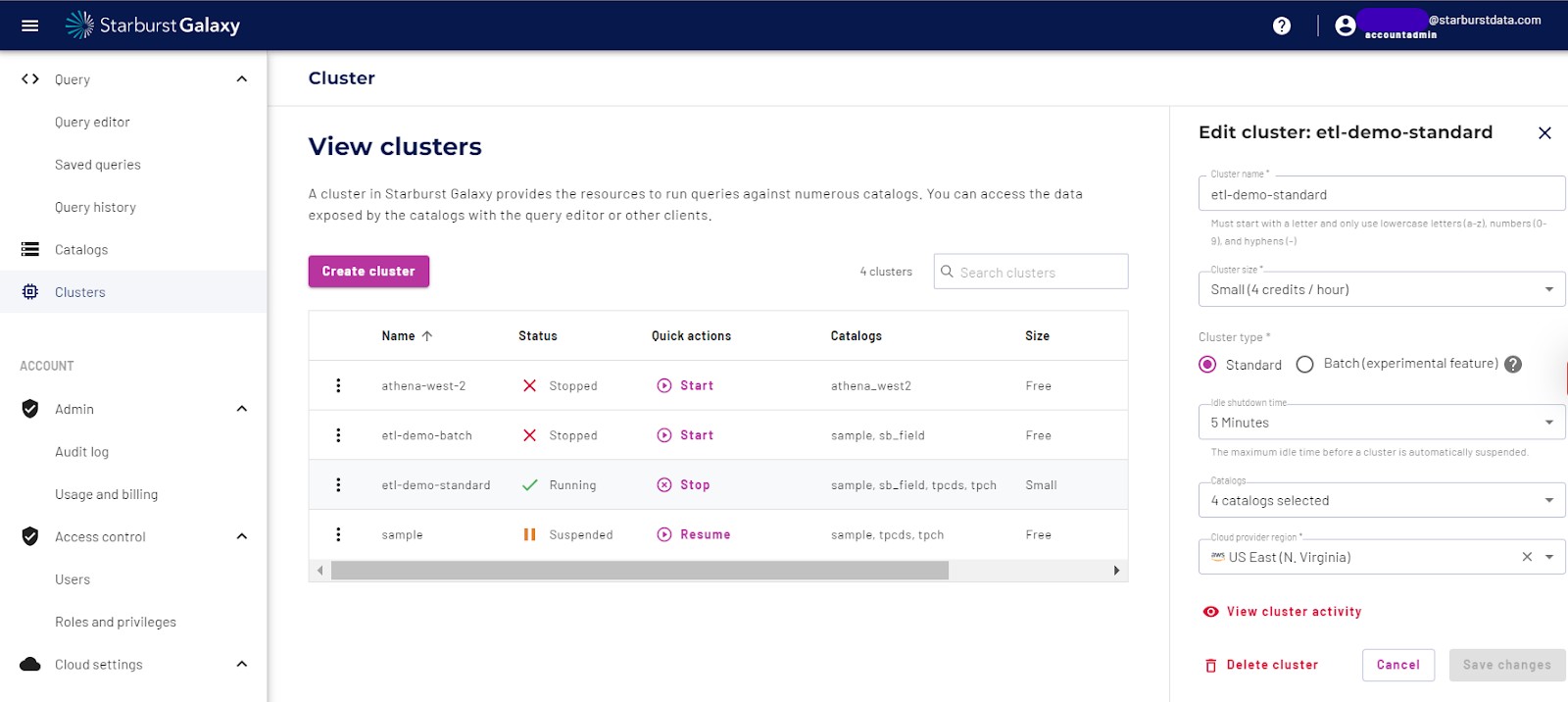
Step 2: Create Clusters & Add Amazon S3 Catalog
With Starburst Galaxy, cluster management is easily accessible in the UI, allowing users full control of setup and management, such as:
- Start, suspend, stop clusters
- Configure catalogs to be used in a cluster
- Select cluster size based on your current needs
- Configure your autoscaling ranges based on your optimal price/performance metrics
Configuring a cluster is as simple as choosing a name for the cluster, adding the catalog we’ve just created, choosing a cluster size (larger clusters process jobs faster but cost more credits/hour), and selecting resource-intensive query processing mode (only use this mode if you are using the cluster for long-running workloads like ETL/ELT jobs). Resource-intensive clusters help to mitigate “out-of-memory” errors you might experience with other query engines. You can also select advanced options like setting up the idle shutdown to automatically suspend the cluster when not in use and directly add role permissioning to the cluster in the creation process.
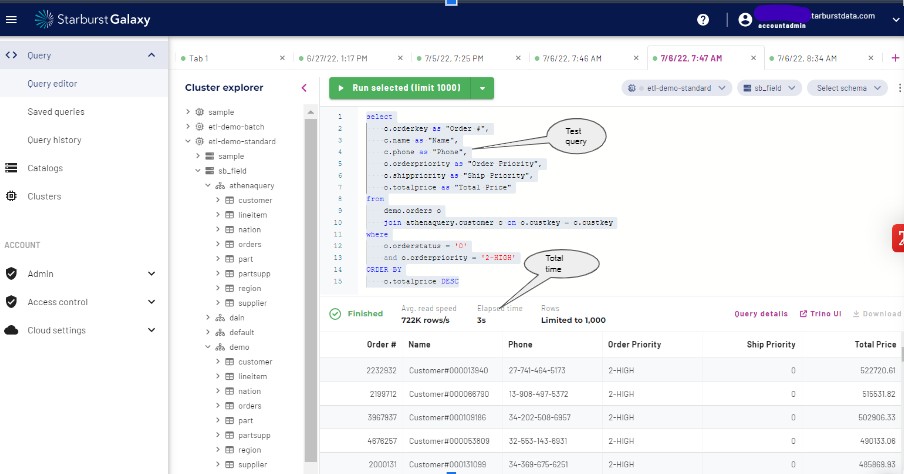
Step 3: Running Athena queries in Starburst Galaxy
In the Athena query editor, run a simple query joining data between two S3 buckets with a filter to limit the amount of records. Now compare the run time and functionality between Athena and Starburst Galaxy:
AWS Athena has limited functionality in the query editor. The lack of query execution plan means that analysts can’t see what is going on behind the scenes, thus cannot understand where the bottlenecks are and how to tune the query for better performance. The only statistics you can see is how much data was scanned, which means how much this query will cost. However, without visibility into how the query engine works and executes the query, you can’t tell how that number was calculated. This is one of the first reasons why it’s called a ‘black box’. When queries fail or hang, you may similarly have a lack of visibility into the reason but we will touch on that topic later.

With Starburst Galaxy’s built-in query editor, you can easily edit and quickly query your data from catalogs. Query details show exactly what’s happening in the underlying engine, allowing users to understand how Trino executed the query. These details allow you to tune your query for performance.
Run the same query in Starburst Galaxy and compare the time it took using the same amount of resources. You should notice the amount of time is less.
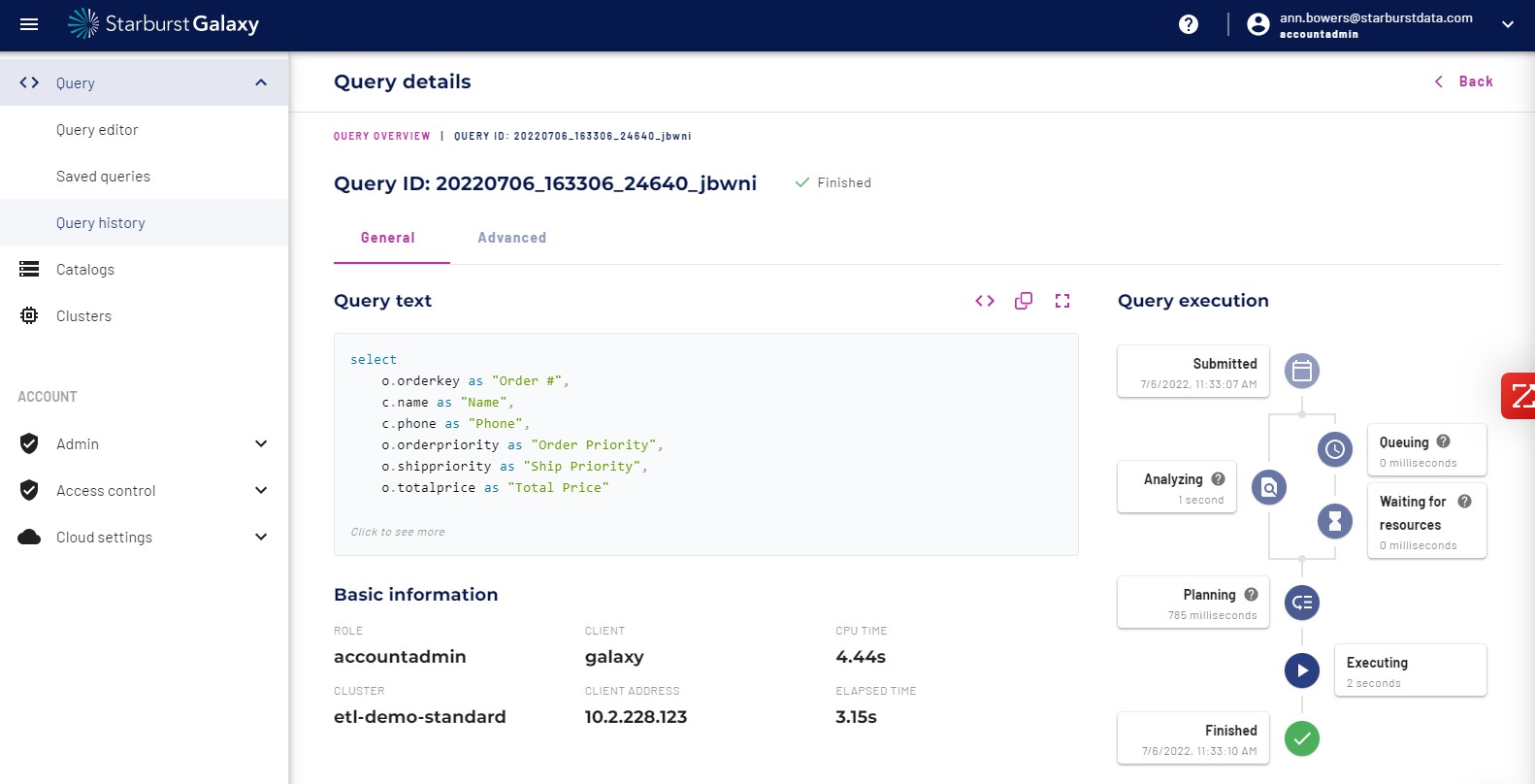
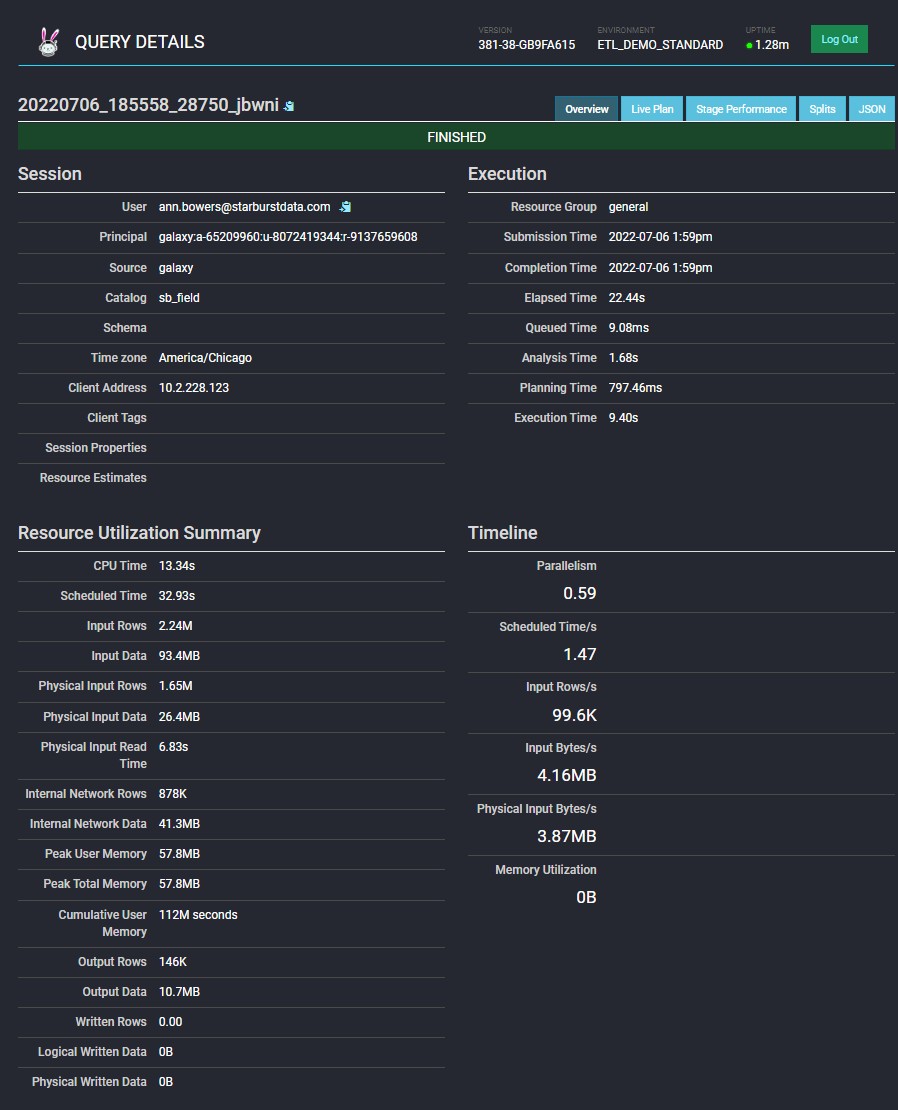
Let’s take a look at what query details in the Query History section.

In the Query History section General tab, this high level information is displayed along with the execution plan in a nice visual flow.
In the Advanced tab, the query plan shows detail level execution of each step of the query execution. This allows for analysts to understand the steps which Trino took to plan out the query, how resources are being used, where the bottlenecks exist, and where tuning may help with performance.
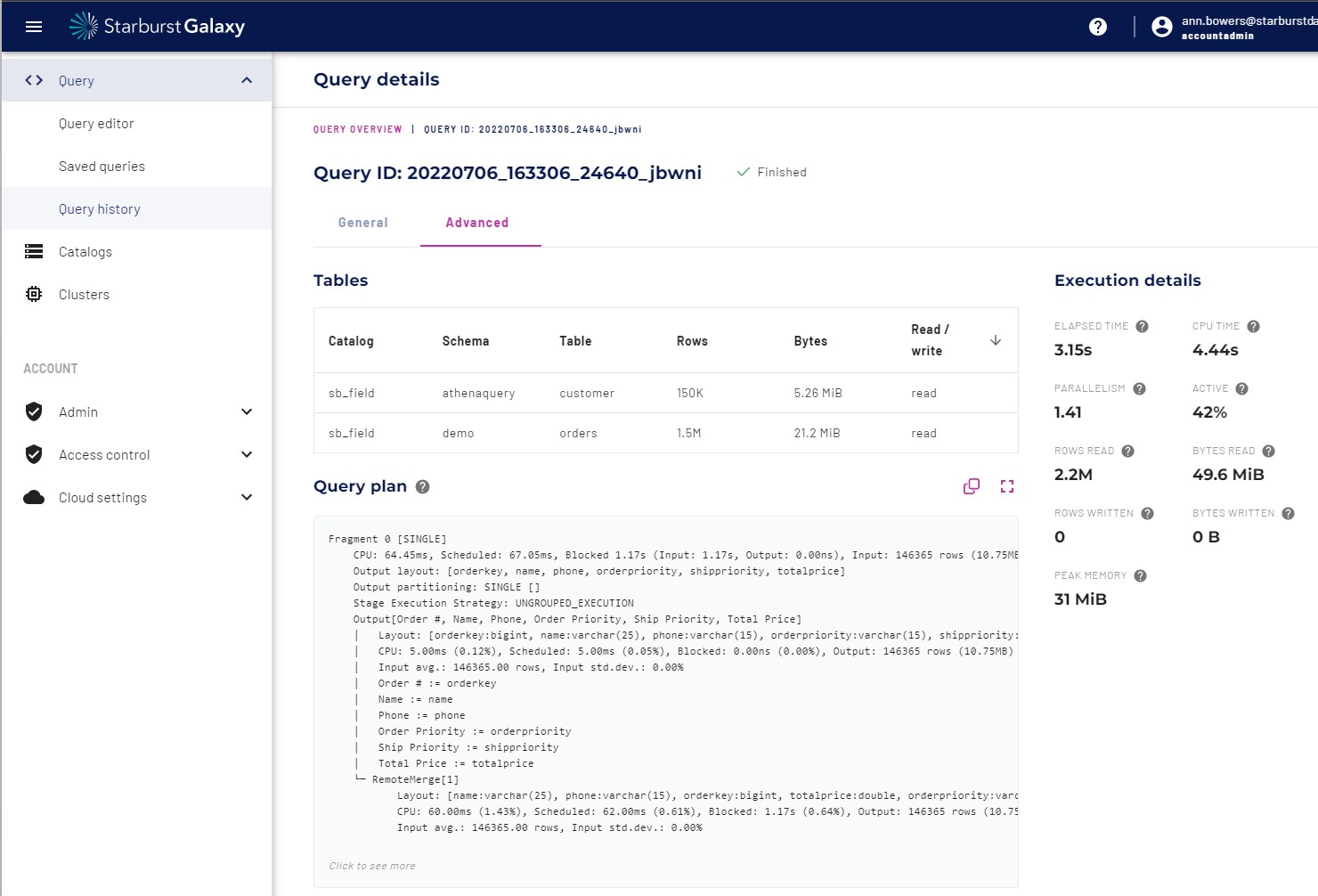
The ability to digest and understand the query plan will help with performance tuning and address any data conversion issues. Most of the time these issues can be fixed with a slight change in data types or query construct.
In Starburst Galaxy, you also have access to the Trino UI which gives more insight into the query details.
Ultimately, Starburst Galaxy is a platform designed to accelerate your time to insights. The platform enables near real-time access to all of your data sources directly from the platform’s SQL editor or your business intelligence/analytics tool of choice. Starburst Galaxy helps organizations build an agile data culture by providing a single point of access to your data lake, cloud data warehouses, RDBMS, and more.
In summary, using Athena queries in Starburst Galaxy is a very simple process. Follow the simple steps above, and you’ll be well on your way to unlocking new critical business insights for your organization.




