
Customers sometimes ask how they can make Trino even faster. One of my first questions back to them is “what are you using for your storage layer?” I often get a puzzled look back, then I explain that Trino is like having a very fast race car but if you don’t give it a nice, fast road to travel on, then you are severely limiting it. Let’s go into further details.
Since Trino is an in-memory query engine, it can only process data as fast as the storage can serve up that data. Sometimes this is under your control and other times it’s not. The diagram above illustrates the different types of storage that your data may reside in which can be queried by Trino.
When we talk about storage performance, it usually falls into two categories which are latency and throughput. Latency is the time it takes to get the data to the end user and throughput is the amount of data the query is reading over time. Think of throughput as the size of hose so the larger the hose, the more water can get through. Latency would be how fast the water can get from one side of the hose to the other.
When Trino users submit queries, they want them to return as fast as possible no matter how much data is involved. This of course depends upon numerous factors which the underlying storage plays a crucial role in determining the time it takes to execute queries.
The diagram below illustrates the different throughput storage layers. Distributed storage such as AWS S3, Azure ADLS and HDFS (Hadoop Filesystem) generally provide the highest throughput for queries which can span terabytes of data.
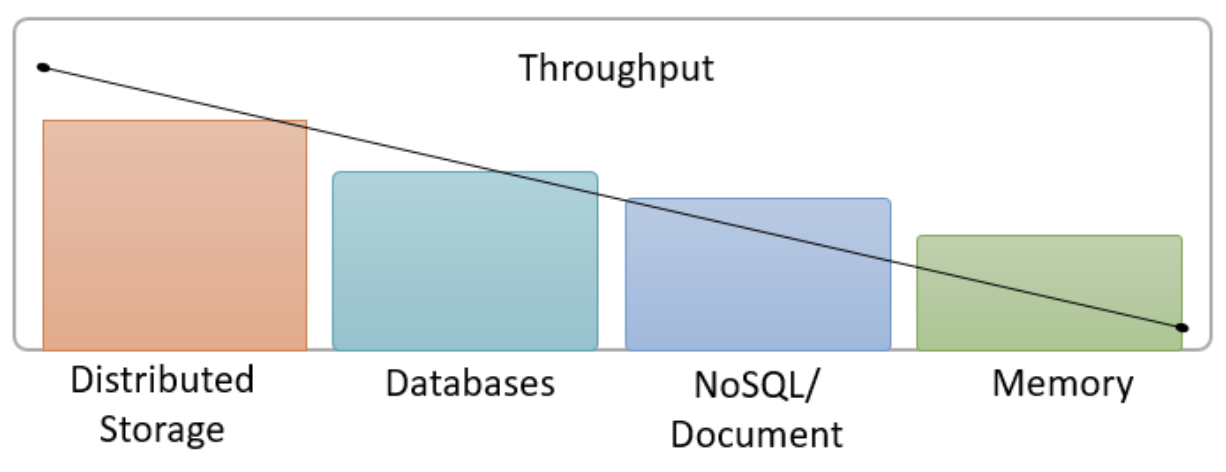
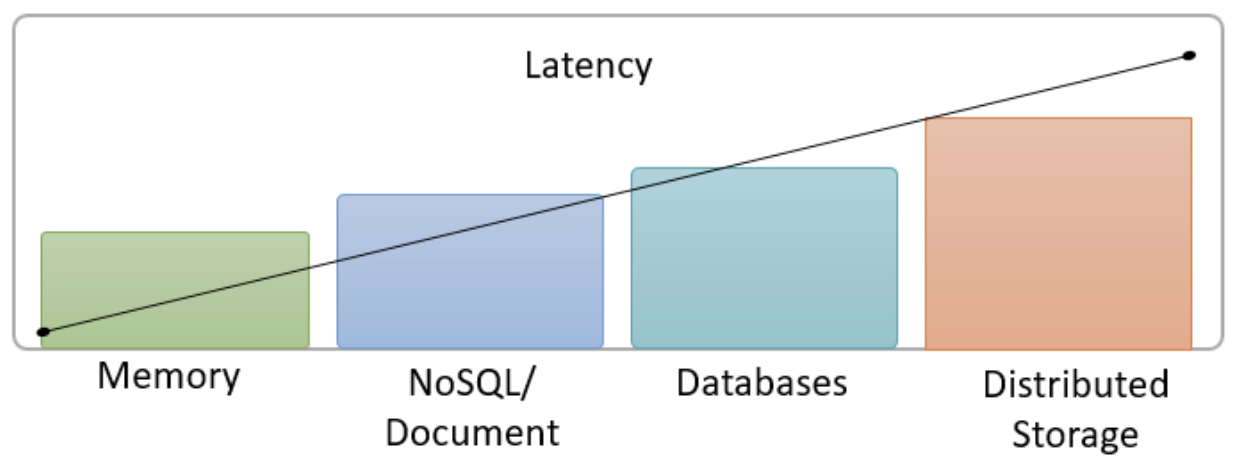
For latency, of course memory (or RAM) is the lowest followed by NoSQL/Document type systems with distributed storage being the highest.
Depending on the use case and performance requirements, there are options to get data to the appropriate storage to meet these demands. The following are a few use cases that our customers have encountered and how they solved them.

Use Case #1 – Low latency, real-time queries for custom application
This customer created an analytical application which mostly executed queries over many terabytes of data. However, there were a few cases where a user would type in a search criteria that would query a very small dataset. An example would be a list of states or regions. The service level agreement (SLA) was < 1 second for these types of queries. Although the data was on S3 storage, the response time wasn’t meeting the SLA so they moved these small data sets to indexed PostgreSQL database tables.
The result was the ability to provide response times for both types of queries ensuring their end-user experience was within their SLAs. This also satisfied the ability to keep their architecture simple by continuing to use Starburst Trino as the main entry point for the application.

Use Case #2 – Frequent querying of low-performing database system
One of our customers had just adopted Starburst Enterprise in their environment and wanted to add a legacy Oracle database to their list of data sources available to their users. The only issue was they were afraid this extra usage would degrade performance too much on this system. Since they had a very large Hadoop system, it made more sense to copy the relevant tables using simple “create table as” statements using Trino from that Oracle system to Hadoop a few times a day. Users would query the data in the Hadoop system which can take advantage of Trino’s MPP parallel engine and return results much quicker as well as reduce the extra load on the Oracle system.
The result was providing a much needed data source to users without hurting the performance of the Oracle source system. This is a great example of using the power of Trino and distributed storage to offload access from a slower system by easily replicating data.

Use Case #3 – Short term storage during ETL process
In our third use case, a company has a morning process where they create many rollup/aggregation tables and then execute numerous reports using Power BI. The data for these reports come from numerous systems and there are many temporary tables used in this process.
The solution is to build these temporary tables in the fastest storage available. In Trino, this is the memory connector or any distributed storage that is available. (note the diagram above) If the data is small enough, the memory connector can be used to provide lightning fast, temporary table storage (note – the memory connector isn’t meant for long term storage). If the tables are larger, then distributed storage can be used to get the fastest performance while writing and reading this data.
Based on your needs, there are plenty of knobs available in Trino to improve performance. When our customers implement Starburst Enterprise as their “query fabric”, it is important for them to look at their environments in a holistic manner. In order to meet strict SLAs and provide the ultimate user experience for their users, it’s important to consider the many different methods to meet these expectations using a variety of different storage layers available to Trino.
Contact us for more information or if you need help architecting your own “query fabric”.




