
As companies shift their analytical ecosystems from on-premise to cloud and try to avoid “data lock-in”, we’re noticing some very interesting data patterns. This series of blog posts will describe what we’re seeing from our customers including what is working and what isn’t.
In each post for this blog series, we’ll cover 5 different patterns which are:
- Hybrid Distributed Data Source and RDBMS: This pattern calls for both a relational data base system and a distributed store such as S3, Azure’s ADLS or HDFS in order to benefit from functionality in both
- Data lakehouse: Emerging data pattern where a majority of data management and analytics leverage distributed storage similar to the first pattern
- Data Mesh: In this recently created and rapidly adopted data pattern, data is accessed in different “domains” and accessed/combined together using a federated query engine such as Starburst’s Trino
- Migrations: This isn’t really a data pattern per se but it’s worth mentioning because it allows companies to migrate from system to system without encountering long downtimes and potential data quality issues
- Multi-Location: Some companies had data and resources spread out among multiple cloud providers as well as on-premises which leads to a challenge for data access
One of the not so well-known data patterns we see is the mixing of databases and data lakes or distributed storage systems. Pairing a database system along with low-cost, distributed storage (S3, ADLS, HDFS) allows the separation of data between dimensional type data (customer, product, reference) and fact type data (events, sales, IoT).
Database systems
Decades of experience and in-depth features to handle relational data and make them a great place for constant inserting and updating of data. This is a feature that data lakes have traditionally struggled with as object/distributed stores weren’t designed for this but it’s the sweet spot for RDBMS.
Low cost, distributed Data Stores (S3, Azure’s ADLS and HDFS)
This type of storage is low cost, redundant, and highly performant. It makes a perfect place to store what we call “write-once, read-many” data which is typically events, IoT, transactions, and measures.
Why not combine the best of both worlds? Especially since any modern ingestions tools/language supports these systems. The following diagram depicts this architecture and we’ll go over the different aspects of this data pattern.
There is a lot going on in the diagram below so let’s go through each section of it.
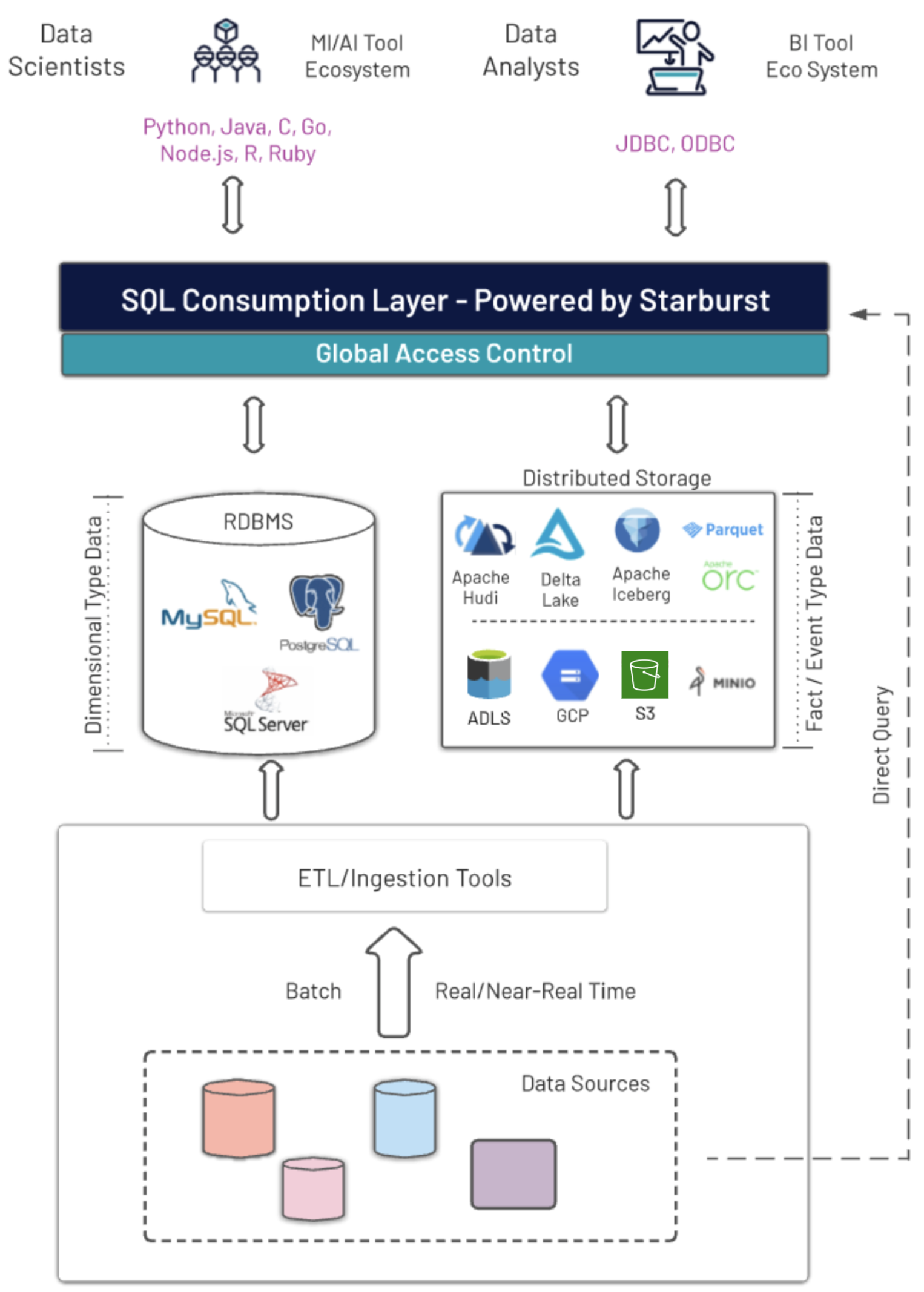
Data Sources
At the bottom, you have numerous data sources that range from databases to noSQL systems to real-time streaming systems such as Kafka. The rate at which this data is ingested into these systems depends primarily on business rules and data SLAs.
ETL/ELT/Ingestion Tools/Languages
These technologies have drastically changed in the last 10 years. Going from primarily one ETL tool to hand coding to newer, lighter ETL and ELT tools such as Upsolver, A2B Data, Spark and dbt. Traditionally, this process was the hardest part of analytics which required not only data ingestion skills but also business knowledge to integrate the data properly to be consumed by data analysts. As we will see below, this step is still an integral part of analytics but with query engines like Starburst, querying data where it lives has become a very powerful option.
RDBMS
The traditional database system is still king when it comes to storing, updating and retrieving data. Not traditionally built for many terabytes of data, its sweet spot is managing mutable data that changes on a frequent basis. Some examples are customer information, product descriptions and reference data. Additionally, most modern databases provide an option to store the data as columnar which in some cases can increase performance on most analytical queries. (great article regarding this )
Distributed Storage
The idea of a single storage infrastructure within a company that was high performant, redundant and able to easily scale had eluded companies for as long as I can remember. Hadoop first delivered on this promise by providing virtually unlimited storage using “commodity hardware” which was further simplified by companies like Amazon with AWS S3 object storage. The only downfall is these storage options aren’t great for updating data.
SQL Consumption Layer
This is where the rubber meets the road. Being able to treat the data in a database system and in a distributed data store as a single data source transparently to end-users is achieved by a federated query engine provided by Starburst. Federated queries are “pushed” down to the database when needed and joined with the distributed data store. Data can be moved between both systems based on business requirements and SLAs.
Direct Query
Sometimes moving data takes time so allowing end users to query the data sources directly is one of the benefits of a federated query engine that Starburst offers based on the Trino (formerly PrestoSQL) open-source project. With over 30+ connectors and role-based access control down to the column and row level, it’s easy to provide access to virtually any data source within your company.
Here are some pros and cons of combining a relational database with a distributed store:
Benefits of combining a relational database with a distributed store
- Low cost, high performing analytical repository.
- Best of both worlds with database handling immutable data and the distributed storage handling mutable (also known as write one, read many).
- Aggregation and rollup tables can easily be created and stored on distributed storage for maximum performance.
Challenges of combining a relational database with a distributed store
- Two systems to maintain although RDBMS have become mostly self-managed. (in the cloud)
- The need to update data in the distributed data store. There are technologies such as Delta Lake and Apache Iceberg to handle these situations which we’ll cover in the next blog post about lakehouses. Starburst offers a Delta Lake connector to create, insert, update, delete and select data so we have you covered)
In this data pattern, combining a low-cost, highly performant distributed data store along with a proven database technology results in a highly scalable and flexible architecture. It requires a bit of thinking “outside the box” but we have customers that have deployed a successful analytical environment with Starburst as the query engine.




