



History of Trino (Formerly PrestoSQL)
In Fall 2012, a small team of four engineers – Dain Sundtrom, David Phillips, Martin Traverso, and Eric Hwang – started working on the Presto SQL query engine at Facebook. It was designed to phase out the slow and tedious Hadoop and HDFS MapReduce jobs being run on the Hive data warehouse. By Spring 2013, the first version was successfully rolled out. Later that year, Facebook open sourced Presto under the Apache License. In 2018, Martin, Dain, and David left Facebook and forked the Presto project under the new Presto Software Foundation so they could better serve the open source community under the new name PrestoSQL. In December 2020, PrestoSQL was rebranded to Trino, and the Presto Software Foundation was renamed to the Trino Software Foundation.
Trino query engine
The Trino query engine provides a quick and easy way to allow access to datasets from a variety of sources using industry standard ANSI SQL, in the exact same dialect as the Presto SQL engine. End users don’t have to learn any new complex language or new tool; they can simply utilize existing tools for analytics with which they are comfortable.
Trino is best-known for handling ad-hoc data analytics workloads, and it shines when reading and federating data in a data warehouse or data lake. It also has a fault-tolerant execution mode which trades off some speed for reliability, making it very effective at handling batch ETL/ELT workloads and insertions.
It is important to stress that though Trino understands SQL, it does not provide the features of a standard database. Trino is not a general-purpose relational database and does not store data, and you will need to use Trino’s connectors to query your database, data warehouse, or data lake.
Trino connectors and data sources
Trino comes with a number of built-in connectors for a variety of data sources. Trino’s architecture fully abstracts the data sources it can connect to, which facilitates the separation of compute and storage. The Connector SPI allows building plugins for file systems and object stores, NoSQL stores, relational database systems, and custom services. As long as one can map the data into relational concepts such as tables, columns, and rows, it is possible to create a Trino connector. And with Trino, users can register and connect to multiple data sources, running federated queries that access all of an organization’s data at once, providing the user with a holistic view of their entire data ecosystem. This makes Trino an OLAP (online analytical processing) system. There is no need to perform a lengthy ETL process to prepare data for analysis, because Trino can query data where it lives.
Trino has connectors for traditional SQL databases like MySQL, PostgreSQL, Oracle, SQL Server; for non-SQL databases like MongoDB, Cassandra, and ElasticSearch; and for modern data lakes like Hive, Iceberg, Delta Lake, and Hudi.
Using Trino to run SQL queries on data lakes
One of the most popular uses of Trino today is to connect it to a data lake. A data lake is a single store of data that can include structured data from relational databases, semi-structured data and unstructured data. It can include raw copies of data from source systems, sensor data, social data and more. The structure of the data is not typically defined when the data is captured. Data is typically dumped into a data lake without much thought about accessing it. Trino has become the choice for querying the data lake due to its high performance at scale. Unlike other options available today, Trino’s concurrency is limited only by the size of your cluster, which can be scaled up and down as required.
How can you run Trino?
The Trino documentation has tutorials on the three key ways to get started with Trino: running it locally with Linux and Java, through a Docker image, or with Kubernetes. All three are relatively easy to do, and from there, you can configure it to suit your use case, connect to BI tools, use the Trino CLI, or connect it to GitHub for zero-cost reports.
Trino also has a wide variety of clients, including Starburst Galaxy, and the Trino website has a client list that shows off its Python, R, Ruby, Node.js, and a breadth of other ecosystems.
Trino general architecture
Trino is a distributed system that runs on one or more machines to form a cluster. An installation will include one Trino Coordinator and any number of Trino Workers. The Trino Coordinator is the machine that users submit queries to. The Coordinator is responsible for parsing, planning, and scheduling query execution across the Trino Workers. Adding more Trino Workers allows for more parallelism and faster query processing.
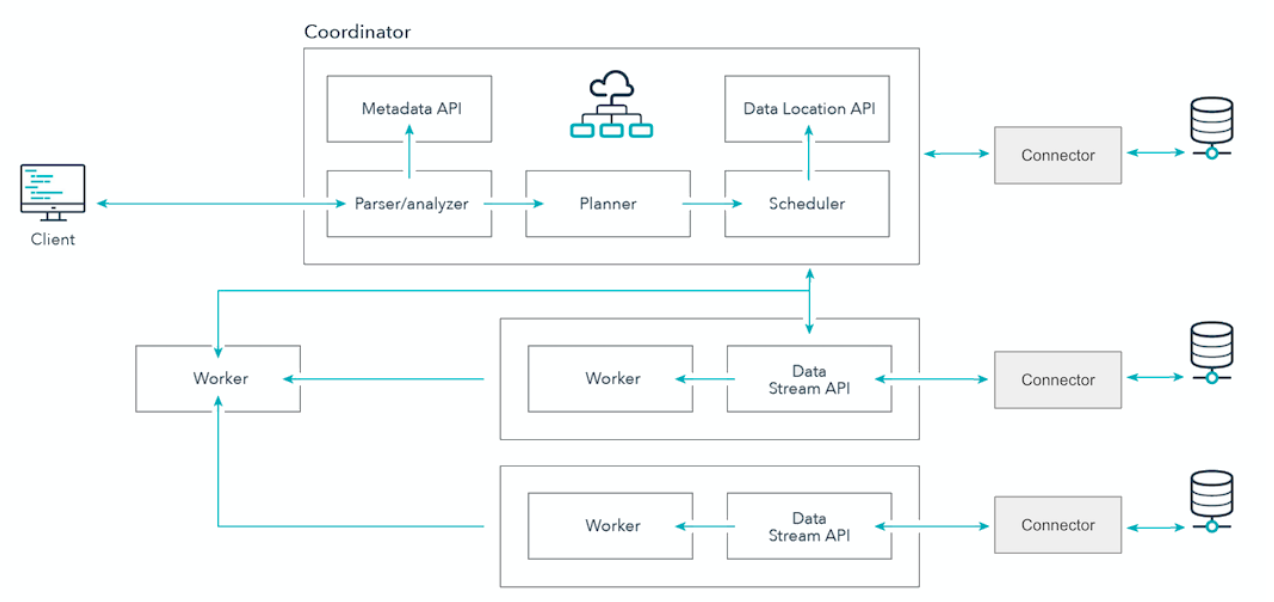
It has internode parallelism over nodes connected using a shared-nothing architecture. Data is partitioned into smaller chunks and distributed across these nodes. Once they arrive at a particular machine, they are processed in parallel over multiple threads within a particular node. This further segments the work to be done over the big amounts of data.
For more information, see our blog on the architecture of Trino’s Hive connector.
How Trino runs SQL queries so fast
By design and as part of its default operation, Trino does not rely on checkpointing and fault tolerance methods which are popular in many other big data systems. While it adds resilience, fault tolerance requires expensive and extremely slow writes to disk that add a tremendous amount of latency.
Trino was primarily designed to be used for interactive analytics, and if you run queries to interactively probe data, you should see results within seconds to minutes. At those speeds, it’s not worth the time it takes to checkpoint any work if the query has such a quick turnaround. The catch is that this also requires the system to run reliably and with few issues, which Trino does. In practice, Trino is known to manage even larger ETL jobs that take up to hours to complete with a very low rate of failure. However, for even larger workloads where speed is less of a concern, Trino’s config settings can be changed to run it with fault-tolerance, sacrificing some of its blistering speed to ensure a negligible rate of failure.
Other elements that make Trino fast are its ability to push queries down to the source systems where custom indexes already exist on the data, dynamic filtering to avoid reading data that will not be used in JOIN statements, and a cost-based optimizer which ensures work is being distributed efficiently and effectively across all worker nodes. Though it’s an open source project, the standard for code contributions to Trino is incredibly high, and this standard helps avoid regressions or additional complexity which would otherwise slow a project of its scale down.
Presto vs. Trino: The differences
Trino and Presto were once one and the same. In 2018, three of the four co-founders of the Presto query engine left Facebook to create their own community-driven fork of the project, which later came to be known as Trino.
When you compare how things have gone in Trino vs PrestoDB since the fork in 2018, development on Trino has gone at roughly three times the velocity. It boasts additional connectors that aren’t in Presto, better performance across the vast majority of connectors, expanded SQL support, and is much better at handling batch ETL/ELT workloads. The Trino community is more active than ever, and because of this, it connects to a wider variety of clients and tools. Due to the higher-velocity development and suite of additional features, Trino is faster, more powerful, and more versatile than Presto.
See our comparison on Presto vs. Trino for more information.
Try Trino today
The easiest way to start querying your data is with Starburst Galaxy, the simplest and quickest way to get running with Trino.




