
As companies shift their analytical ecosystems from on-premise to cloud and try to avoid “data lock-in”, we’re noticing some very interesting data patterns. This series of blog posts will describe what we’re seeing from our customers including what is working and what isn’t.
In each post for this blog series, we’ll cover 5 different patterns which are:
- Hybrid Distributed Data Source and RDBMS: This pattern calls for both a relational data base system and a distributed store such as S3, Azure’s ADLS or HDFS in order to benefit from functionality in both
- Data lakehouse: Emerging data pattern where a majority of data management and analytics leverage distributed storage similar to the first pattern
- Data Mesh: In this recently created and rapidly adopted data pattern, data is accessed in different “domains” and accessed/combined together using a federated query engine such as Starburst’s Trino
- Migrations: This isn’t really a data pattern per se but it’s worth mentioning because it allows companies to migrate from system to system without encountering long downtimes and potential data quality issues
- Multi-Location: Some companies had data and resources spread out among multiple cloud providers as well as on-premises which leads to a challenge for data access
Continuing our data patterns series, the term “Lakehouse” has been around for a couple of years now and there have been numerous articles written about them including our own CTO Kamil which you can read here as well as this excellent one by one of the godfathers of data warehousing Bill Inmon.
In this blog post, we’ll dive a bit deeper into what it means, how companies are building it and some of the best practices we’ve seen from our customers and the industry.
Data warehouse
Data Warehouses have been around for 40+ years. They were created simply because the questions asked of the data became too computationally intensive for their operational system counterparts as well as the need to join data between different operational systems. The idea was to “pull” data from these different systems into a single database, integrate it, apply business rules, verify the quality and generate standard reports as well as allow ad-hoc queries.
Data lake
As the three “V’s” of data became too much for data warehouses to handle, (veracity, volume and variety) and they became too expensive to maintain (mostly software costs – $500k+ to add another node? ouch…), the Data Lake was born hoping to solve these problems using “commodity” hardware and (mostly) open source software. For certain organizations, they knew the limitations of this technology (no updates/deletes, not standard ANSI SQL,etc..) and set expectations correctly internally while others considered it the end of expensive data warehouses and were already planning the funeral for their warehouses.
Data lakehouse
Many of us in the industry went to bed at night wishing both technologies could merge and we would have the perfect technology:
- Separation of the compute from the storage – this would allow you to bring many/different clusters to work on the data and you could scale both independently
- Updating and deleting the data at a row level – This was table stakes for data warehouses but was impossible in data lakes (without some very hacky insert overwrites…) Watch out, here comes GDPR!
- Data Warehouse querying performance over terabytes of data – Folks that went from the data warehouse to the data lake were usually quickly disappointed in query times going from seconds to minutes to hours
- Ease of ingesting data – probably one of the hardest things to do was to add new data sources to a data warehouse (the dreaded ETL term…) but new technologies have made it easier and the demand for timely data is a requirement vs. a dream
- Scaling – we often saw our warehouses and lakes sit mostly idle during off times and completely overwhelmed during busy times. The ability to scale up and down (brought to us by the cloud providers) to meet demand, made end users happier while saving money.
So, we’re currently in this state right now where numerous companies have both a data warehouse and a data lake. Most of the data ingestion starts with the lake because “it’s cheaper” and then a series of joining, aggregation,etc.. happen to create data sets in the lake and then more finely curated data sets get sent to the warehouse where rollups and aggregates are created.
Now, if you have made it this far, the obvious choice is to try to create one common place to hold data for analytics – the Lakehouse. There are other emerging ideas/processes like data mesh that are questioning this thought process (which we’ll cover in the next blog post) but this is reality for most large companies. The dream of a single place to store most/all of our analytical data is very close to becoming reality.
There are table formats (Delta, Iceberg) and processing engines that work with these formats that are bringing the data lake closer to a warehouse. They offer features such as DML (data manipulation language – update delete, merge), increased query performance over Terabytes of data, and guaranteed data integrity (prevention of bad and orphaned data) in the data lake.
When we look at both technologies then include the new Lakehouse architecture, I came up with the following feature table:
Data warehouse architecture vs data lake architecture vs lakehouse architecture
Feature |
Data Warehouse |
Data Lake |
Lakehouse |
Interactive queries |
Yes |
Yes |
Yes |
Manipulation of data |
Yes |
No |
Yes |
Active data warehousing |
Yes |
No |
No |
Petabytes of data |
No |
Yes |
Yes |
Separation of compute and storage |
No |
Yes |
Yes |
Data Integrity (constraints) |
Yes |
No |
Yes* |
(* – some processing engines handle data integrity in the Lakehouse)
We’ll break down each of these features:
Interactive queries: The ability to provide millisecond/seconds query results over gigabytes and in some cases terabytes of data.
Manipulation of data: Traditional updating/merging/upserting of data. An example is customer information.
Active data warehousing: Coined by Teradata many years ago, this is the concept of constantly updating data in a warehouse. Think Fedex package updates or high volume customer updates which the Lakehouse just wasn’t designed for.
Petabytes of data: Although MPP data warehousing vendors always claimed you can just add more nodes, there was a limit as I’ve witnessed personally. When the data volume > 1 petabyte, the only option was to add another warehouse appliance. Data Lakes on the other hand were designed to hold many petabytes of data.
Separation of compute and storage: One of the most important innovations in the last 5 years has been the separation of compute and storage. In the past, when you wanted to expand your warehouse or even data lake, you added “nodes” which were compute and storage. Even if you didn’t need more storage or compute, they always came together.
Data Integrity: In the past, as we transitioned from a OLTP type database to a data warehouse, there was always lively debate about whether to add constraints on top of tables. On one hand you aren’t allowing bad data to enter your system but on the other hand, you slow down data ingestion because it doesn’t fit into a rule. (it usually goes into “bad” tables for someone to review which oftentimes never happened). The lakehouse is starting to add light integrity rules such as valid values on columns.
As you can see from the table above, we’re very close to feature parity with the traditional data warehouse for numerous use cases.
The diagram below shows a modern day Lakehouse. The need to also store data in a data warehouse is becoming less and less of a necessity. Rollups, aggregations,etc.. can be created right in the lakehouse. These structures traditionally lived in a data warehouse but with the advances of networking, distributed storage performance (S3,etc..), file management features, and cost-based optimization, the lakehouse can serve these structures while achieving the same high performance as these legacy systems.
Data Lakehouse Architecture
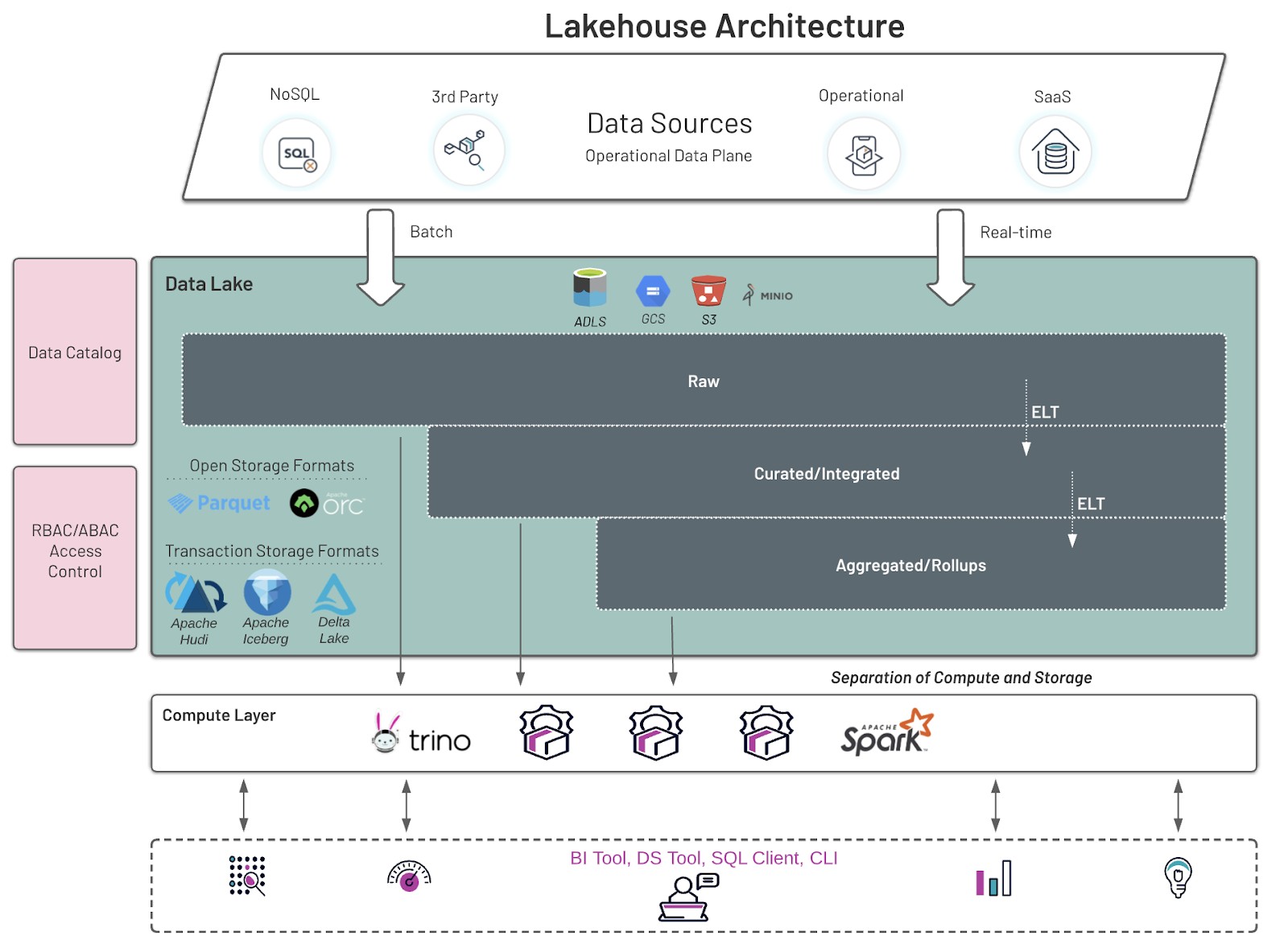
Some highlights from the diagram above:
- Data of many different varieties are either streamed in real-time or via batch from numerous different source systems
- Data lands in a raw area in distributed storage such as AWS S3
- Data is then curated and integrated with other data sets
- Lastly, this data in then aggregated/rolled up for quick analysis/reporting
- All 3 layers are available to clients using a variety of tools. These range from SQL to programming libraries such as Python.
- Full cataloging and Role-Based Access control is implemented to protect sensitive data and only allow authorized users to access the data in the different levels
- Transactional data sets can be created using newer technologies such as Delta Lake and Apache Iceberg. This allows for the updating of data in a Lakehouse
“The best ever data lake analytics platform to discover, organize, consume data & data processing…[Starburst] provides the fastest & [most] efficient analytics engine for data warehouses, data lakes, [and] data mesh.”
User in Financial Services
The modern data lake or Lakehouse contains the best of both the data warehousing and data lake worlds. Having the ability to ingest terabytes of data via streaming or batch processing then provide this data immediately to a wide range of users is critical to any business these days.
The Lakehouse is the next generation of analytical repositories for companies of all sizes. There are many new tools on the market to make it much easier to ingest and analyze data and with the simplified architecture shown above, the vision of a fully functional data lake is finally possible.
Starburst, built upon the most popular open source SQL query engine Trino, provides many lakehouse features such as materialized views, file optimization (small file problem) and even full dbt integration. For more information, just contact us.




