I saw this one on the Trino slack posted by João Pedro Boufleur
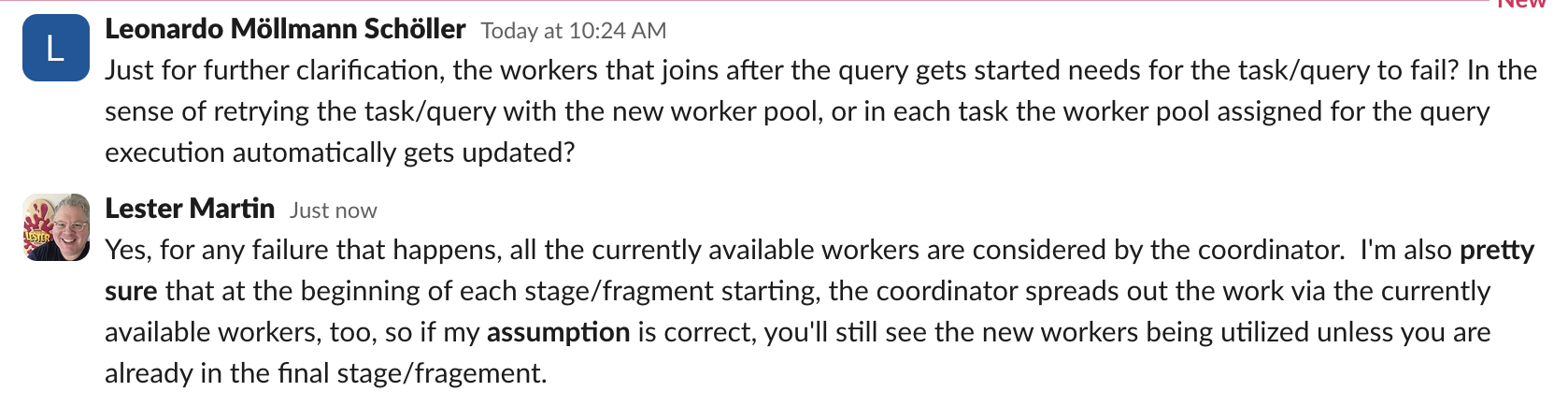
I have a question about Trino’s scheduler and scaling behavior.
If I start a query when only one worker is available, but more workers join the cluster during query execution, will Trino utilize those new workers for the ongoing query? Or does Trino’s coordinator only allocate and schedule work based on the cluster topology at the time the query starts? In my case, a query started with one worker and failed due to insufficient resources, but by the time it failed there were more workers available—yet it didn’t seem to redistribute the tasks or retry with the additional capacity.
Could someone clarify how worker topology changes during query execution affect running queries in Trino? Is dynamic redistribution or rescheduling possible, or are all assignments fixed at query start?