i try load csv file from S3 bucket to Startburst galaxy with CTAS,
but csv file there are one column for description so the word include ’ ,’
even i already transfer csv file be UTF-8 , the column has “xxx, xxx” ,
but after loading file , it will become more rows.
Can you anonymize a few of the records that work AND don’t work so I can try it out to see if I can figure out what’s going wrong. Generally speaking, it is all working for me as you’ll see below.
FILE
field_a,field_b,field_c
1,"no problems",9
2,"has, comma",8
3,"has, two, commas",7
DDL
CREATE TABLE with_commas_as_csv (
field_a varchar, field_b varchar, field_c varchar
)
WITH (
external_location = 's3://MY_BUCKET/comma_test',
format = 'CSV', skip_header_line_count = 1,
type = 'HIVE'
);
QUERY
SELECT * FROM with_commas_as_csv;
RESULTS

NOTES
You could add this additional property, but it is the default.
csv_quote = '"',
Hi, Les
Thanks for replying , actually i find that is column has empty space to make import data more rows.
even it has “” include content.
ID, Comment,User
111, "[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—
if operate the above quick steps, the diagnosis result will uncomplete. “,Michelle
222,”[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",AAA
CREATE TABLE testdata (
ID varchar,
comment varchar,
user varchar
)
WITH
(
– csv_escape = '',
external_location = ‘s3://galaxyaws-asia/testdata’,
format = ‘csv’,
skip_header_line_count = 1,
type = ‘HIVE’
) ;
sounds like you got it all sorted out! nice!! if it is still a problem, let me know and I’ll try to test with the test data you supplied.
Hi. Lester
actually no , just find the column data include space , but the column has include" " , should can import successfully .but row 1 still generate multi row when import .
gotcha; haha! i thought you had it all sorted out already. ![]()
so… with that sample data above I found several problems when I copy/n/pasted it, some of which you can see in this screenshot.

I don’t think you wanted the middle of the 111 record to have a line-split, so I pulled that out.

There is also a “lot” of double-quotes (some that are very vertical and some slanted and some that are two double-quotes next to each other), but I thought you initially where worried about the 111 row having an extra space after 111, and that shouldn’t cause a problem as this simple example shows I added a 999 row with that extra space.
field_a,field_b,field_c
1,"no problems",9
999, "has space before quotes",999
2,"has, comma",8
3,"has, two, commas",7
Created an external Hive table.
CREATE TABLE testdata (
ID varchar, comment varchar, user varchar
)
WITH (
external_location = 's3://MY_BUCKET/column_with_space',
format = 'csv',
skip_header_line_count = 1,
type = 'HIVE'
);
And results look good.

SO… I tried the LOTSA-DOUBLE-QUOTES test data that I’m pasting here specifically first.
ID, Comment,User
111, "[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. “,Michelle
222,”[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",AAA
Replaced my simple test file on S3 with this file and then queried the table again.

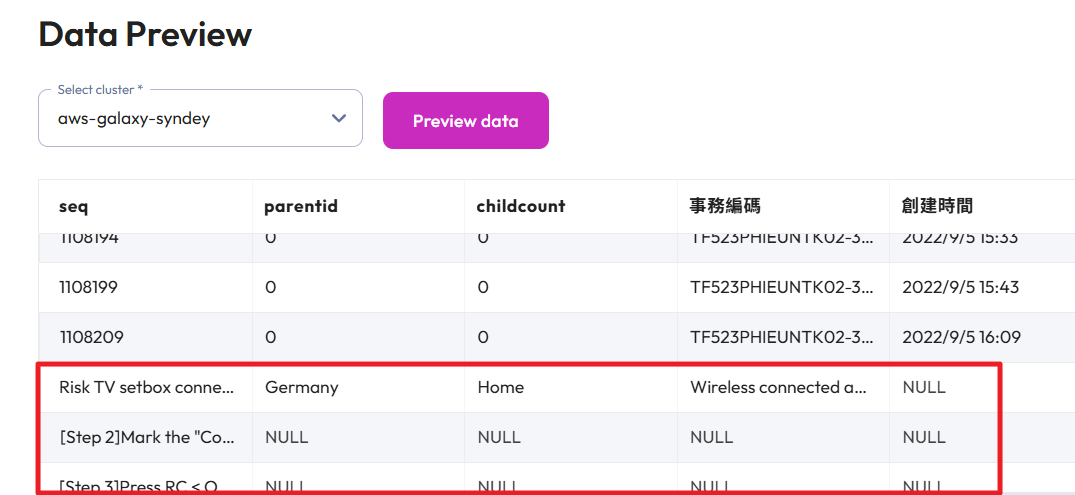
Eeek! Looks terrible!
Here are details from the comment column of the 222 record.
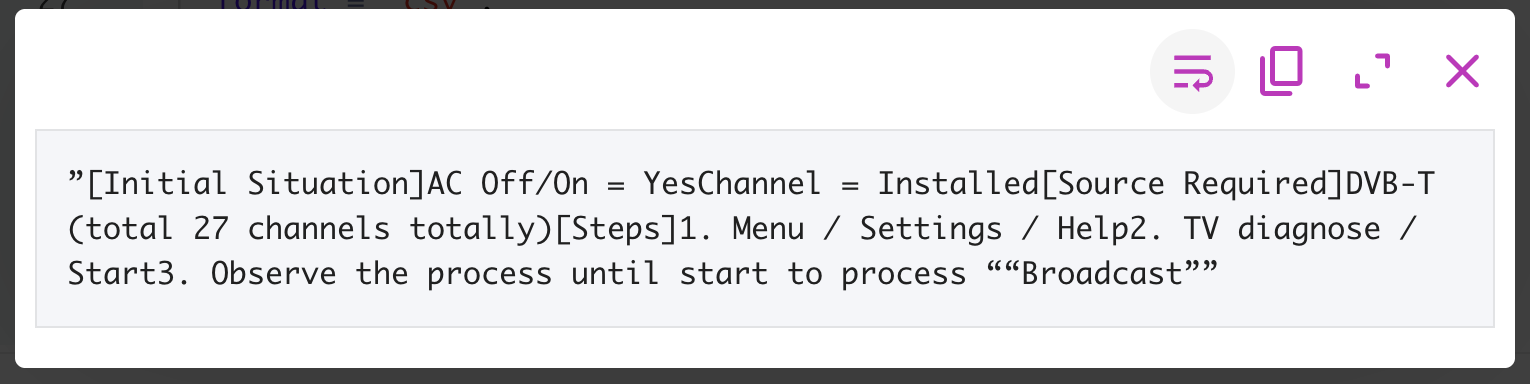
Here is what the user field of the 222 record looks like.
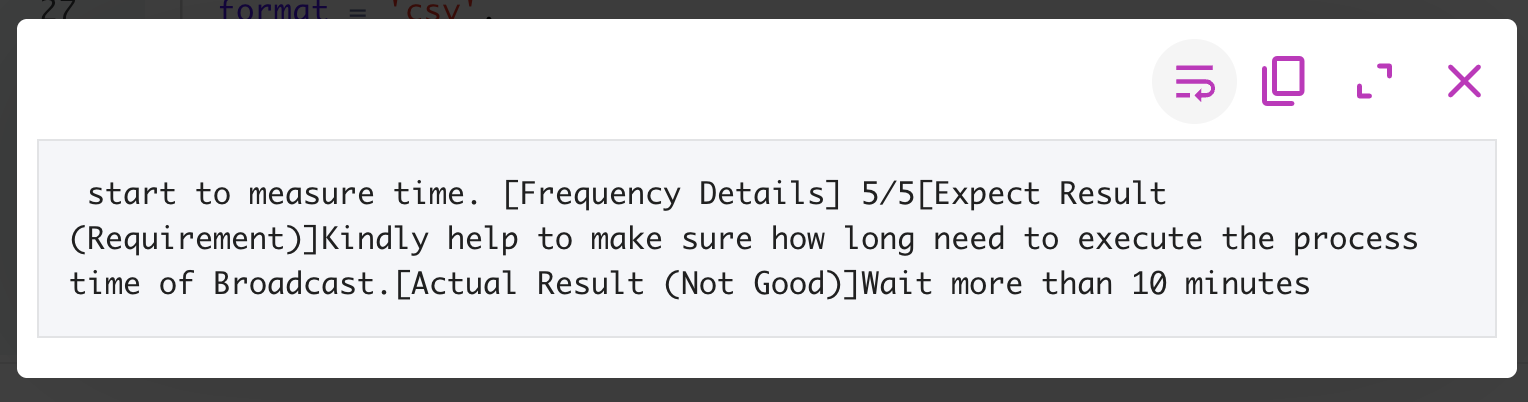
I’m not 100% sure why the 111 row showed NULL for comment and user, but as I look at 222 it does have some logic to the problems showing up. First, notice that the double-quotes are the slanted ones (i.e. ”, not ") at the start of the comment field and it finally hits a comma right where that row breaks.
So… focusing on that row I dropped the 111 record and changed the comment column’s start double-quote to be the “right” one (i.e. ") as you can see below. Note: the end double-quote was already correct.
ID, Comment,User
222,"[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",AAA
This looks good we I swap out the file on S3 and query the table again.

Drilling into the comment column you’ll see it is all in there. Note: I didn’t attack the double (slanted) double-quotes, but I’m guessing you really wanted them as to just have short strings wrapped around a short string and that SHOULD be able to work with using the escape character config, but it will likely require your export to produce whatever that will require.
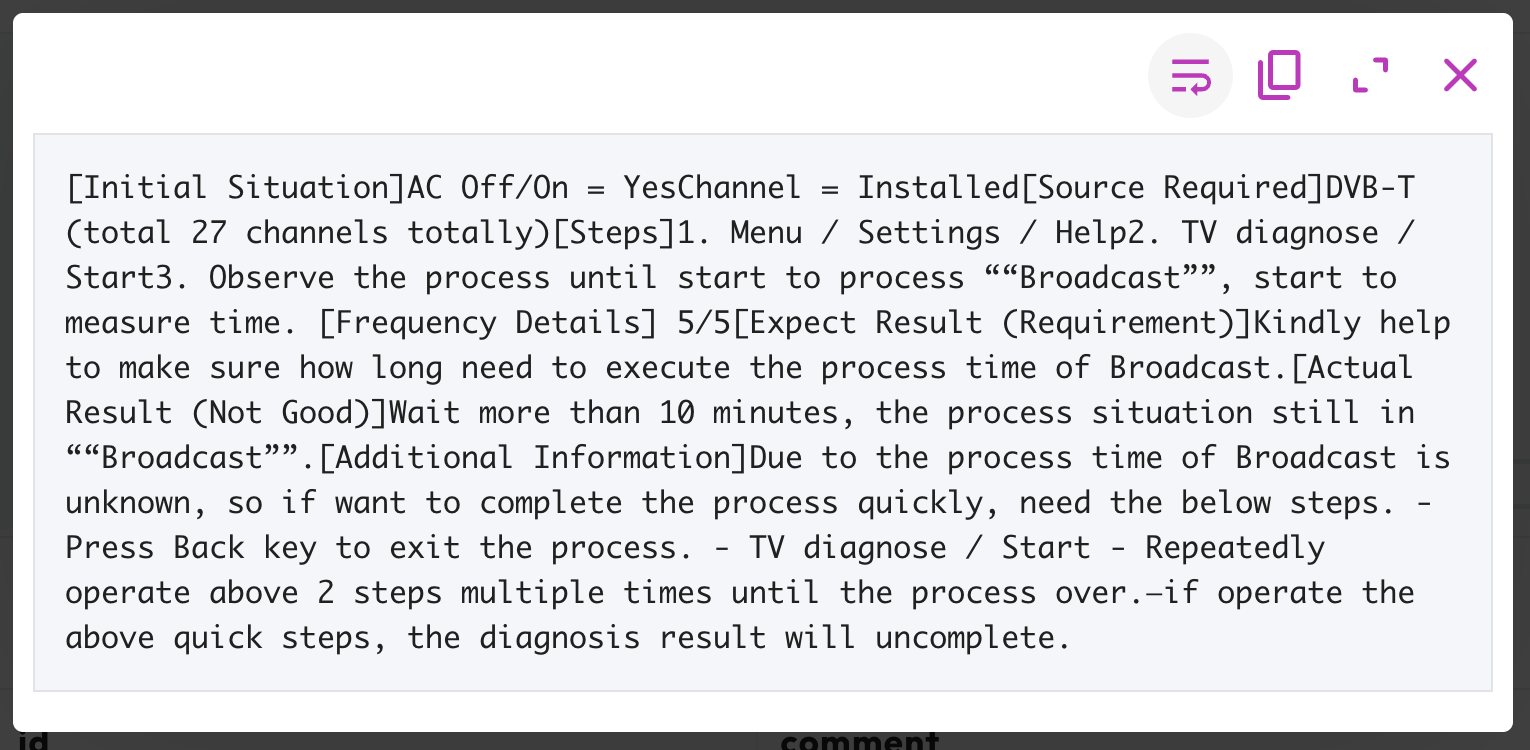
Let’s add that extra space again in the csv file before the comment field’s value.
ID, Comment,User
222, "[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",AAA
As stated at the top of the reply, this doesn’t hurt.

Added the 111 record back in. Left the initial space in it, too. This one was the exact opposite of the 222 record. Meaning the starting double-quote was the vertical one and the ending one was a slanted double-quote (which actually explains much of the problems earlier). So just changed that ” to " then saved and replaced the file to look like this one.
ID, Comment,User
111, "[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",Michelle
222, "[Initial Situation]AC Off/On = YesChannel = Installed[Source Required]DVB-T (total 27 channels totally)[Steps]1. Menu / Settings / Help2. TV diagnose / Start3. Observe the process until start to process ““Broadcast””, start to measure time. [Frequency Details] 5/5[Expect Result (Requirement)]Kindly help to make sure how long need to execute the process time of Broadcast.[Actual Result (Not Good)]Wait more than 10 minutes, the process situation still in ““Broadcast””.[Additional Information]Due to the process time of Broadcast is unknown, so if want to complete the process quickly, need the below steps. - Press Back key to exit the process. - TV diagnose / Start - Repeatedly operate above 2 steps multiple times until the process over.—if operate the above quick steps, the diagnosis result will uncomplete. ",AAA
Ahh… that’s better!!

So… to recap… the only things I did to the data you pasted in earlier were:
- Pulled out that extra line-break in the 111 record
- Changed
“,Michelleat then end of the 111 record to",Michelle - Changed
222,”[Initialat the beginning of the 222 record to222,"[Initial
HOPE THIS HELPS!
Hi, Lester
Thank you for detail testing and suggestion.
About pulled out that extra line-break , this will be user input data need limit them,
just wander when importing csv file, Starburst doesn’t just rely on the presence of quotes ("") and commas (,); it also automatically treats a line-break as the start of a new record .
YW, it was fun! ![]() Starburst (actually the underlying Trino Hive connector) DOES just rely on the quotes and commas AND they can be overridden by the
Starburst (actually the underlying Trino Hive connector) DOES just rely on the quotes and commas AND they can be overridden by the csv_quote and csv_separator properties if needed.
The italicized quotes are actually different characters than the more vertical ones which was a bunch of the problem that I saw in the little dataset you shared. A mixture of the two types and sometimes starting with one and switching to the other one at the end.
But yes… the new-line character is the end-of-record identifier. This isn’t just a Starburst/Trino thing… it has been there since HIve started 15 years ago.
I vaguely remember that Hive itself allows a CREATE TABLE property to be passed in to allow the end-of-record identifier to be something different, but I’m thinking we don’t get to override that with a Starburst/Trino CREATE TABLE statement (I’ve personally never had to do that in all my years of working with Hive & Trino, so I don’t think that’s a big deal).