Last Updated: 2024-01-22
Background
Starburst Galaxy allows you to easily query a variety of data sources. It can also be used to join data from multiple data sources through a single point of access.
It is especially useful when querying data lakes or joining data lakes to data warehouses as a way of enhancing efficiency and reducing cost by shifting data from traditional data warehouses towards inexpensive cloud object storage.
Scope of tutorial
This tutorial will get you started using Starburst Galaxy and help demonstrate the federation of data between a data lake and data warehouse using sample data.
After creating a free Starburst Galaxy account, you can jump right in and start using Starburst Galaxy.
Prerequisites
- There are no prerequisites for this tutorial.
Learning outcomes
Once you've completed this tutorial, you will be able to:
- Create a new Starburst Galaxy account.
- Access sample data included with a Starburst Galaxy account.
- Use SQL to run a test query using sample data, and understand how the query operates.
- Federate data across multiple data sources, including data lakes and data warehouses.
About Starburst tutorials
Starburst tutorials are designed to get you up and running quickly by providing bite-sized, hands-on educational resources. Each tutorial explores a single feature or topic through a series of guided, step-by-step instructions.
As you navigate through the tutorial you should follow along using your own Starburst Galaxy account. This will help consolidate the learning process by mixing theory and practice.
Background
It's time to set up your Starburst Galaxy account. This is designed to be quick and easy - just a couple of minutes.
Once you're set up, you can query sample data or add your own data sources, including data lakes, or data warehouses.
Excited? Let's get started.
Step 1: Navigate to Starburst Galaxy
Starburst Galaxy is accessed through a web browser, although it can also be used in other ways, including a command line interface. This tutorial will focus on using the web UI, as this is the way that most users interact with the system.
To get started, click the URL below to begin signing up.
- In your browser, visit the Starburst Galaxy home page.
- Click the Create new account button.

Step 2: Provide your information
Starburst Galaxy accounts are registered to a particular name and email address. To set up your account, you will need to provide the following information.
- Enter your First Name.
- Enter your LastName.
- Enter Email address.
- Click the Create Account button.

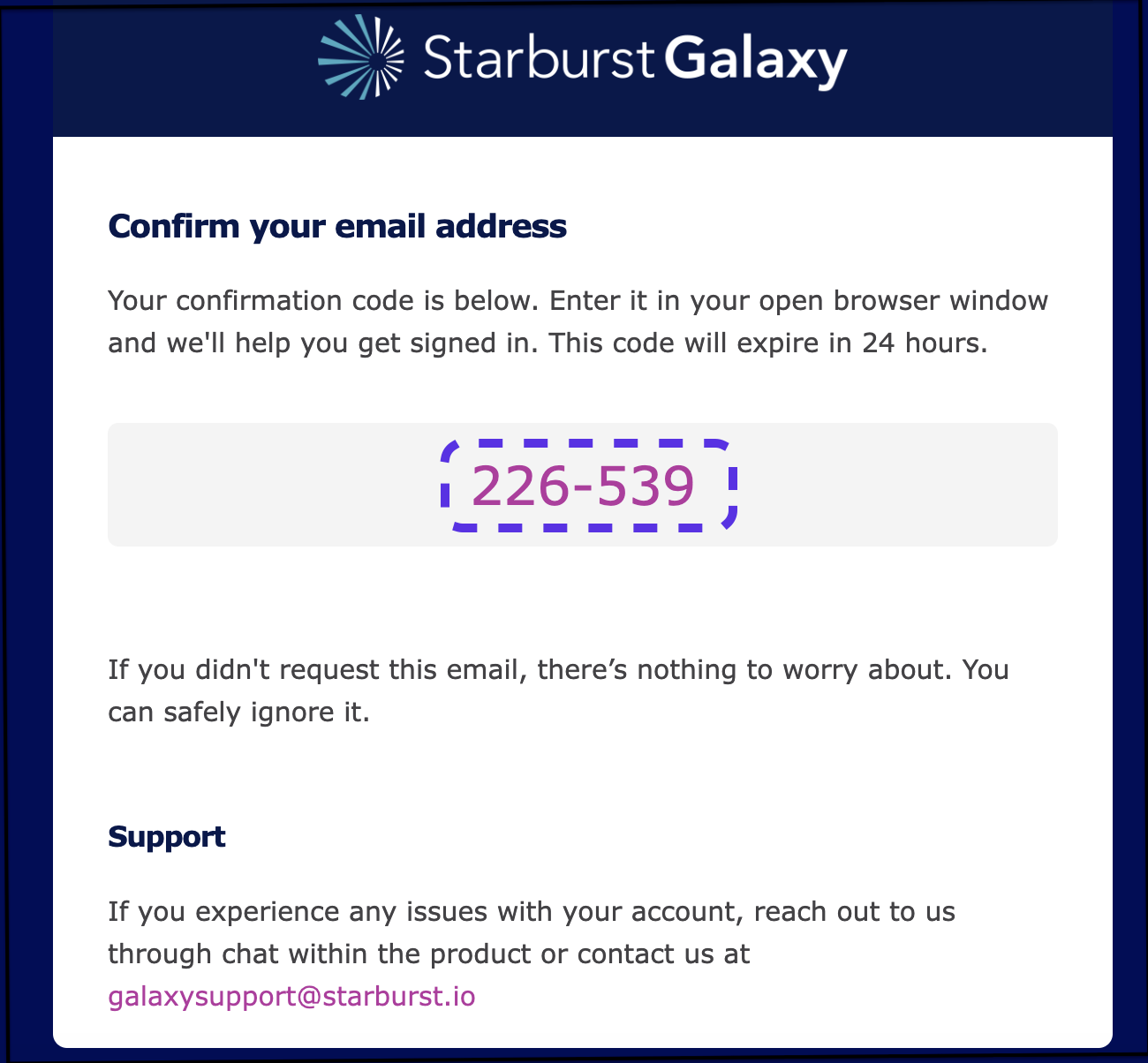
Step 3: Retrieve confirmation code
A confirmation code will be sent to your email address. You will need to copy it from your email into your Starburst Galaxy browser window.
- Copy the confirmation code.
Step 4: Paste verification code into Starburst Galaxy page
Now it's time to paste the confirmation code into Starburst Galaxy.
- Return to the Starburst Galaxy sign in page in your browser, and paste the code from your email.
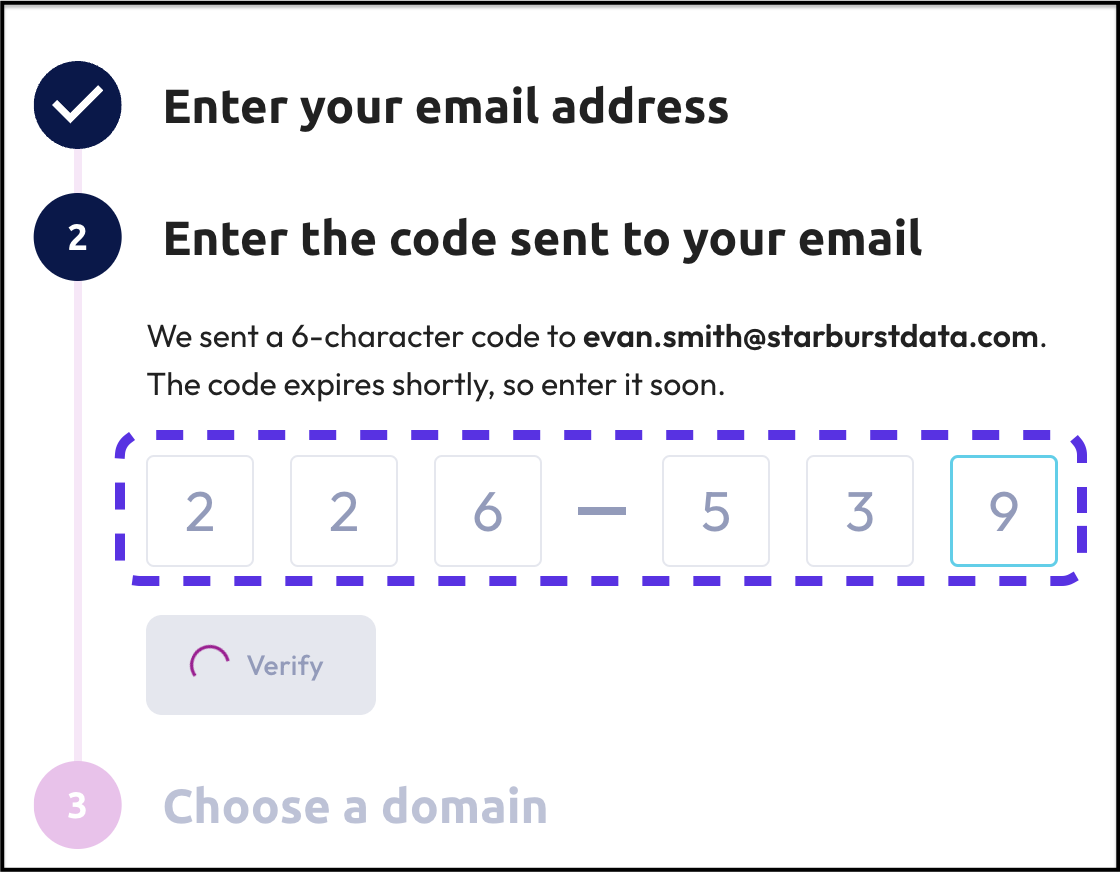
Step 5: Choose a domain name
Starburst Galaxy accounts each include a domain name. Typically this is either the name of the user, or the department or business function controlling the domain. In either case, it should be meaningful to you and something that you will not forget.
Once selected, the domain will become part of the URL used when you sign in to Starburst Galaxy.
- Enter a meaningful domain name in the field provided.
- Click the Create account button.
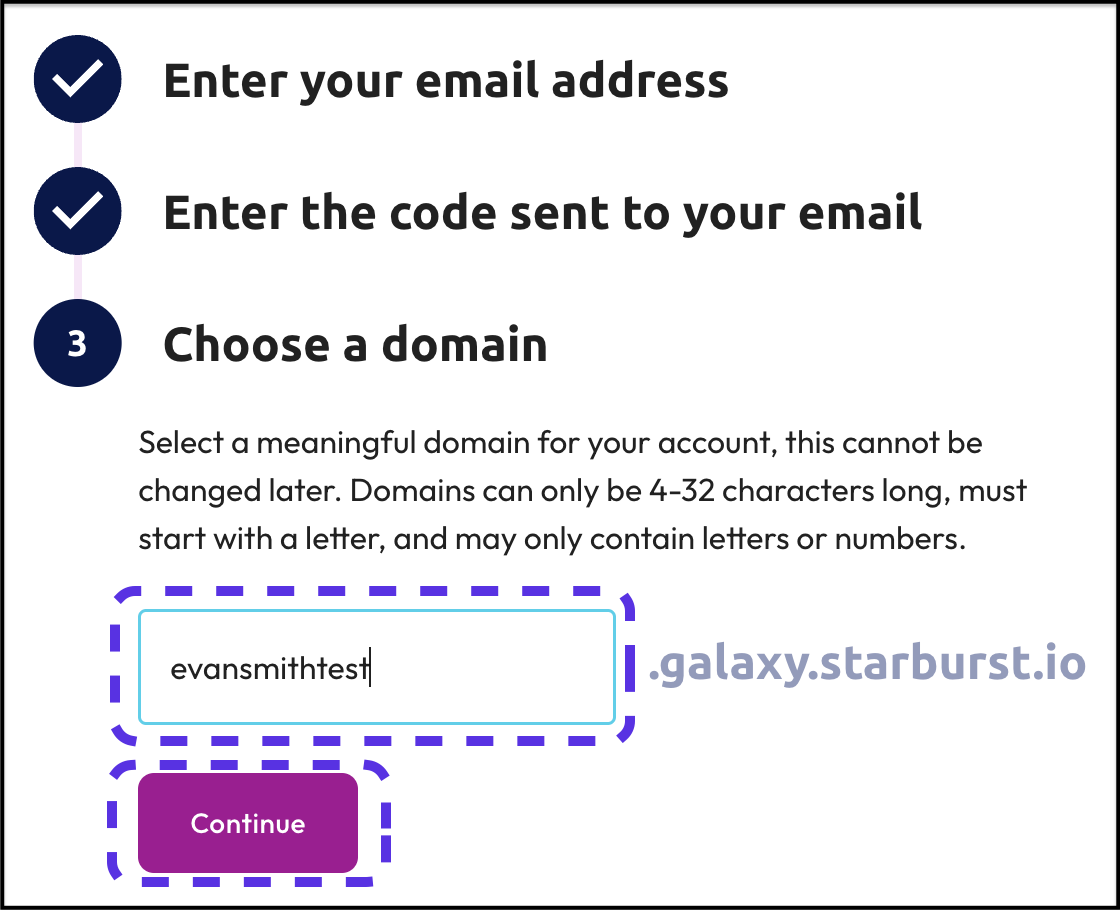
Step 6: Create a password
Now it's time to create a password. This will help protect access to your account. You should never share this password with anyone.
If you need to share access to your account with others, there are more secure ways to do this from within Starburst Galaxy. Future tutorials will demonstrate this process.
- Enter a password in the field provided.
- Click the Create account button.
Step 7: Tell us how you'll use Starburst Galaxy
Starburst Galaxy is used by many different types of people in different ways. Knowing the ways that you'll be using it will help us meet your needs better.
Before proceeding, tell us a bit about how you are going to use Starburst Galaxy.
- Fill out the questionnaire to tell us how you plan to use Galaxy.
- Click Continue when you are ready to proceed.

Background
Starburst Galaxy's main task is to make running queries easy and intuitive, no matter where your data resides. To help accomplish this, it hits the ground running by providing a simple dataset and a few sample queries to get you started.
You're going to begin by using these sample datasets to execute your first queries.
Step 1: Query sample data
Starburst Galaxy lets you use either sample datasets or your own datasets.
In future tutorials, you will connect your own data sources, but for now you can use sample data.
- To proceed with sample data, click Query sample data.

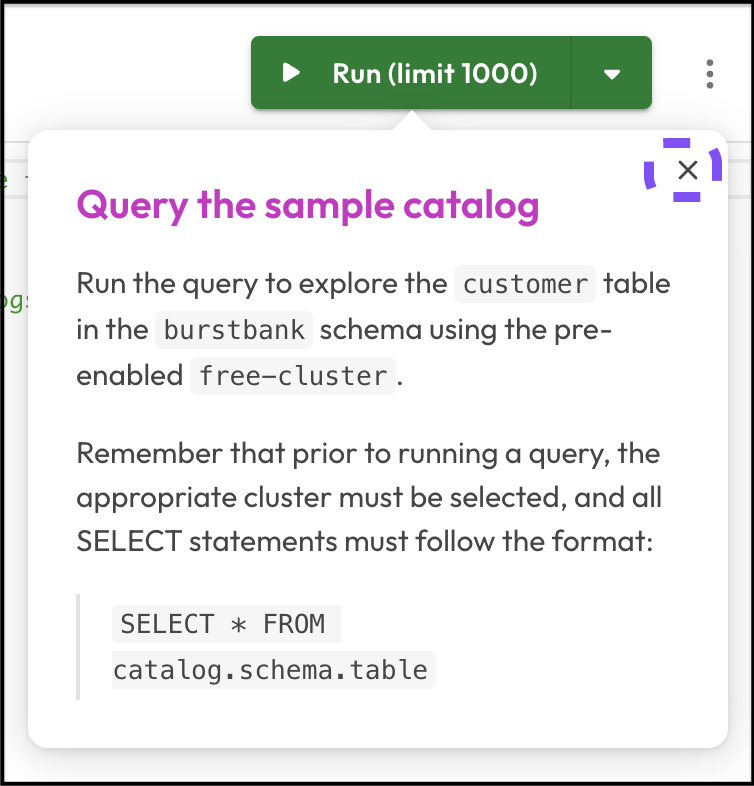
Step 2: Query the sample catalog
Starburst Galaxy includes several test queries when you first launch it. This is designed to help you get up and running quickly.
The queries have been designed to demonstrate the system's capabilities and hit the needs of most users.
Starburst Galaxy will also display a prompt designed to help you understand the user interface.
- Take a moment to read the prompt, then click the x when you are ready to continue.
Step 3: Select Cluster, Catalog, and Schema
It's time to ensure that your cluster is configured properly in the Query editor before you run your first query.
- Ensure that the Cluster drop-down menu is set to free-cluster.
- Ensure that the Catalog drop-down menu is set to sample.
- Ensure that the Schema drop-down menu is set to demo.

Step 4: Query customer table from burstbank sample data
The SQL query that you need is already in the Query editor. This helps you hit the ground running and test your cluster quickly.
- Move your cursor to line 2 with the following code:
SELECT custkey, last_name, country FROM sample.burstbank.customer LIMIT 10;- This query will select data from the
custkey,last_name, andcountrycolumns in thecustomertable located in theburstbankschema andsamplecatalog. - Click Run selected (limit 1000).

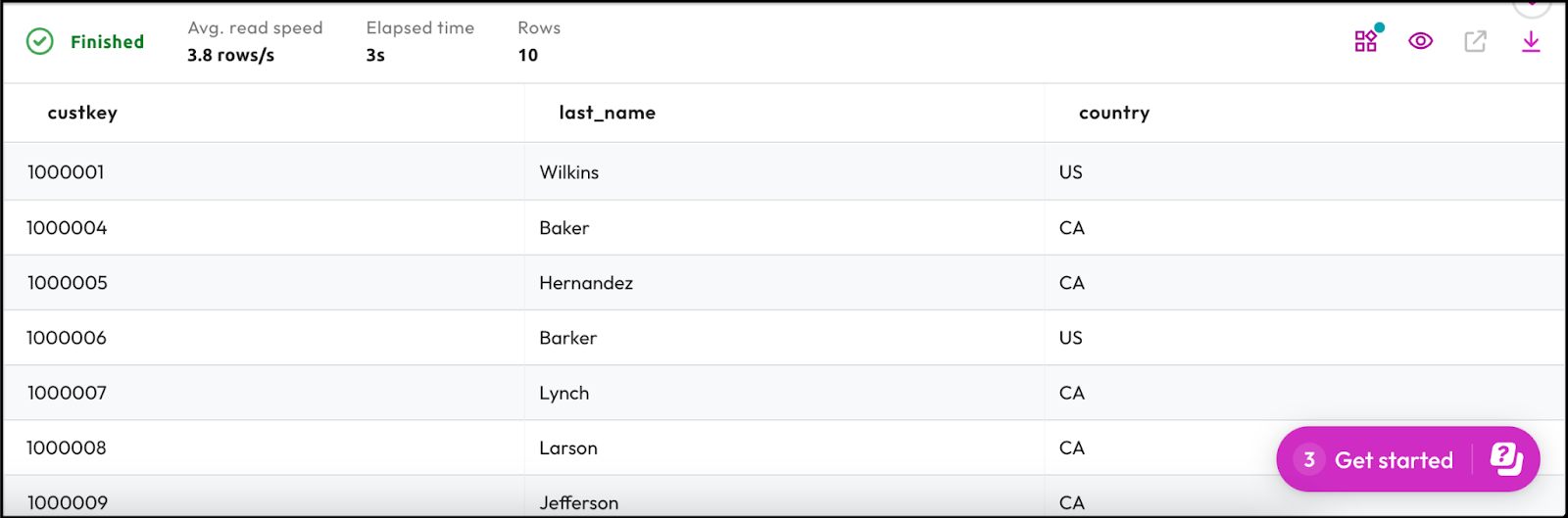
Step 4: View results of first query
Now it's time to view the results of your query. Starburst Galaxy displays the results of your query at the bottom of the page.
- Take a moment to review the results. It should look similar to the image below.
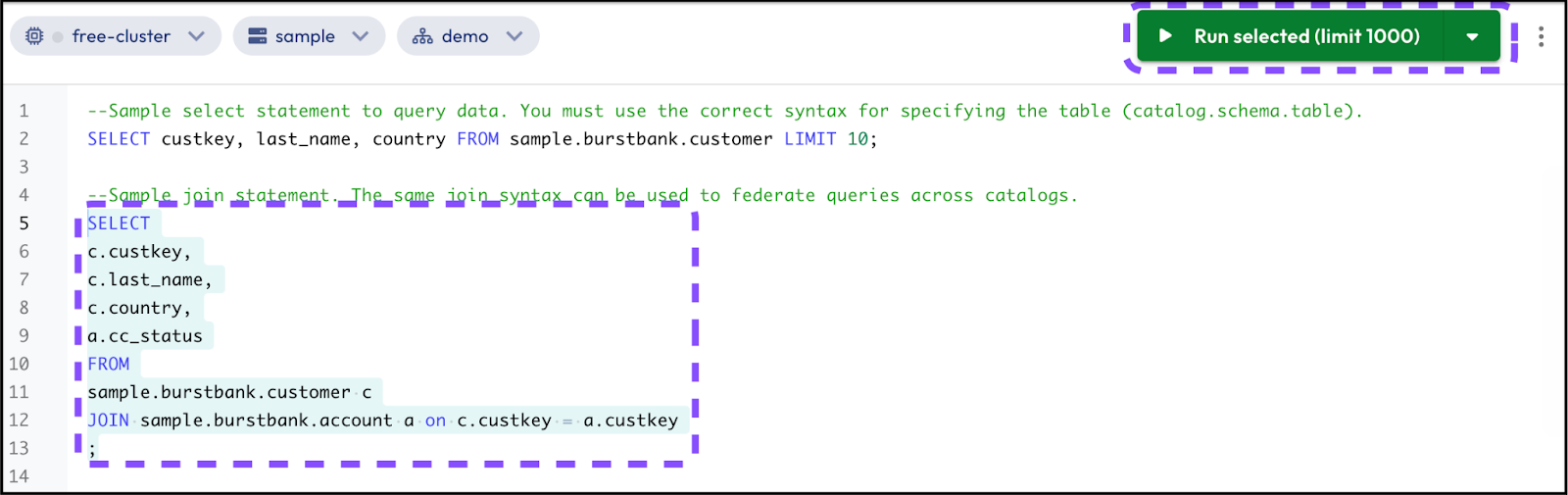
Step 5: Execute join using sample data
Now you're going to run another query using sample data. The second query included with Starburst Galaxy joins data within a single catalog of sample data.
- It selects the
c.custkey,c .last_name,c.country, anda.cc_statusfrom thesample.burstbank.customerandsample.burstbank.accounttables. - Place your cursor on the line with the query or select the text then click Run selected (limit 1000).
Step 6: View results of second query
The results of the second query are displayed below the query editor. This query joins data from tables within the same catalog, but Starburst Galaxy makes it easy to join tables from different data sources using data federation.
The next part of this tutorial will delve into that federation use case, unlocking the power of the open data stack.
- Review the output of this query. Your results should look similar to the image below.
Background
Now it's time to shift gears. To showcase the true power of Starburst Galaxy, you're going to use data federation to join two different data sources.
Many organizations store data in multiple locations for a variety of reasons. It's not uncommon for data to be scattered across data lakes, data warehouses, and databases, sometimes both in the cloud and on-prem.
For this scenario, imagine that you work as an imaginary bank that uses Starburst Galaxy, Burst Bank. This bank has data in many different locations, and it's going to be your job to join two of them.
The scenario below outlines the scenario in more detail.
Take action
Now it's time to use Starburst Galaxy to assist Burst Bank by joining all their datasets together to produce the report they need.
In this exercise, the data warehouse and data lake already exist and the necessary connection information is provided for you in this tutorial.
To do this, you will:
- Configure catalogs to access the data lake and data warehouse.
- Configure a cluster for those catalogs.
- Run a federated query to get the results that Burst Bank needs.
Background
Burst Bank holds payment history information in their data lake. In this section you will use the Starburst Galaxy Data Lakehouse connector to access this data.
Step 1: Create new Catalog
Adding a new data source to Starburst Galaxy requires creating a new catalog for that data source.
- Using the left-hand navigation bar, select Data>>Catalogs.
- Click the Create catalog button.

Step 2: Choose the data source
Data lake object storage is the most popular option for Starburst Galaxy data sources. For this tutorial, we're going to be using Amazon S3.
- Click the Amazon S3 tile.

Step 3: Provide credentials for catalog
Each data source has its own credentials that limit access. You're going to add the credentials needed to access the data lake via Starburst Galaxy. This will create a catalog for that datasource which will keep track of those credentials in the future.
- In the Catalog name field, input
lakehouse_burst_bank. - In the Description field, input any description of your choice.
- In the Authenticate with section, select AWS access key. Note: It is also possible to authenticate using a cross-account IAM role. Future tutorials will cover this method in detail.
- In AWS access key for S3 field, enter the following access key for the data lake:
AKIAYUW62MUVVQ2OP34U - In the AWS secret key for S3 field enter the following secret key for the data lake:
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 - Scroll down to complete the next step of the setup.

Step 4: Choose the metastore configuration
Now it's time to select the metastore configuration. Starburst Galaxy lets you choose from several options for metastore. You can mix and match metastores and data sources in whatever way makes sense for you. For this tutorial, we're going to select AWS Glue, using the US East North Virginia region.
- Select AWS Glue.
- Set the AWS Glue region to US East (N. Virginia).
- In the Default S3 bucket name field, enter
query-plan-labs-data-external. - In the Default directory name field, enter
burst_bank. - Select the Use the authentication details configured for S3 access box.
- Scroll down to complete the next step of the setup.

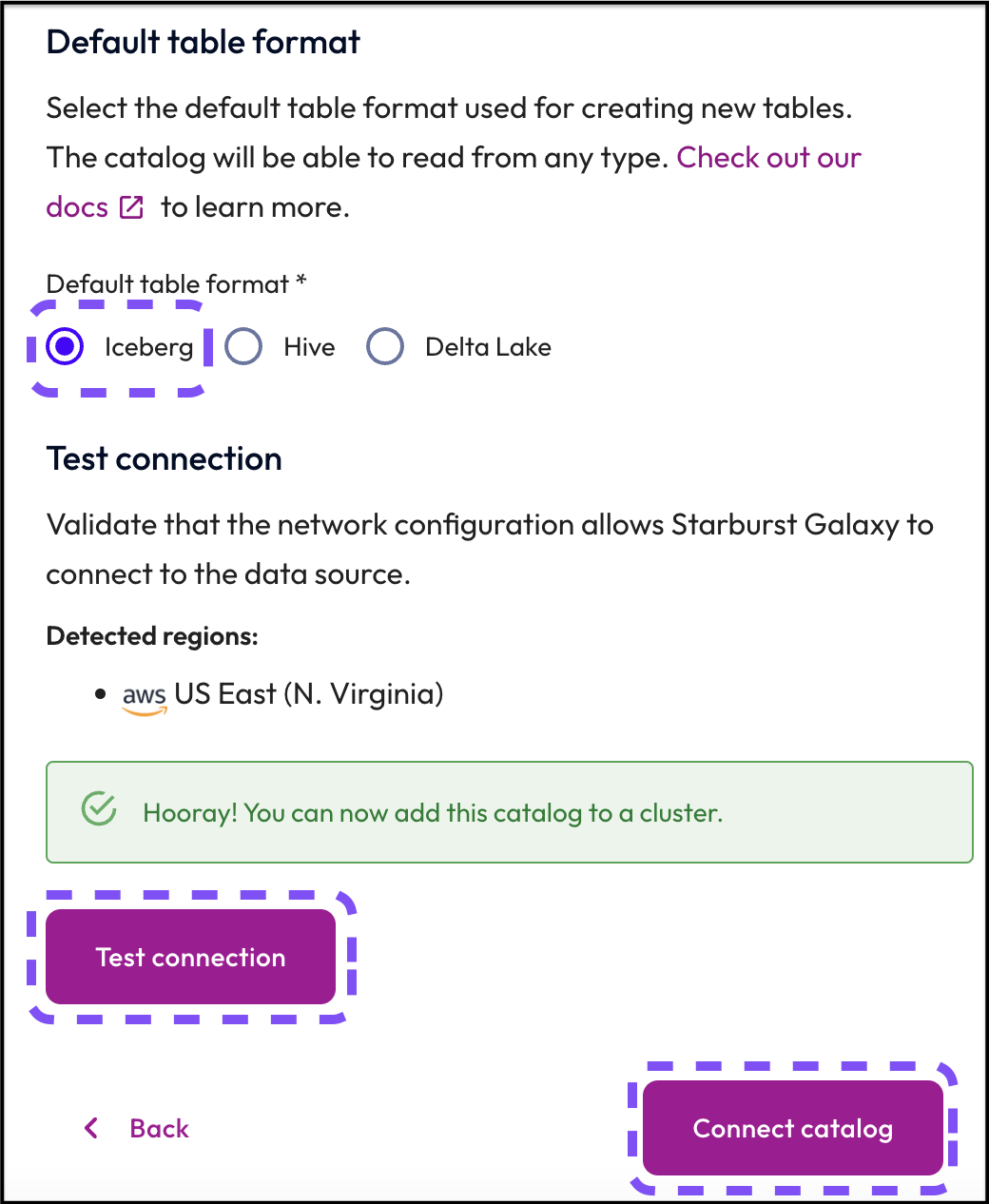
Step 5: Add final catalog details and test the connection
Table formats control the way that data is stored when it enters the data lake. Today you're going to be using a modern, open table format known as Iceberg. Starburst Galaxy is also able to read other table formats like Hive and Delta Lake, but Iceberg is by far the best table format for most users.
- Set the Default table format to Iceberg.
- Click the Test connection button.
- Confirm you see the Hooray! You can now add this catalog to a cluster message.
- After you have confirmed a successful connection, click the Connect catalog button.
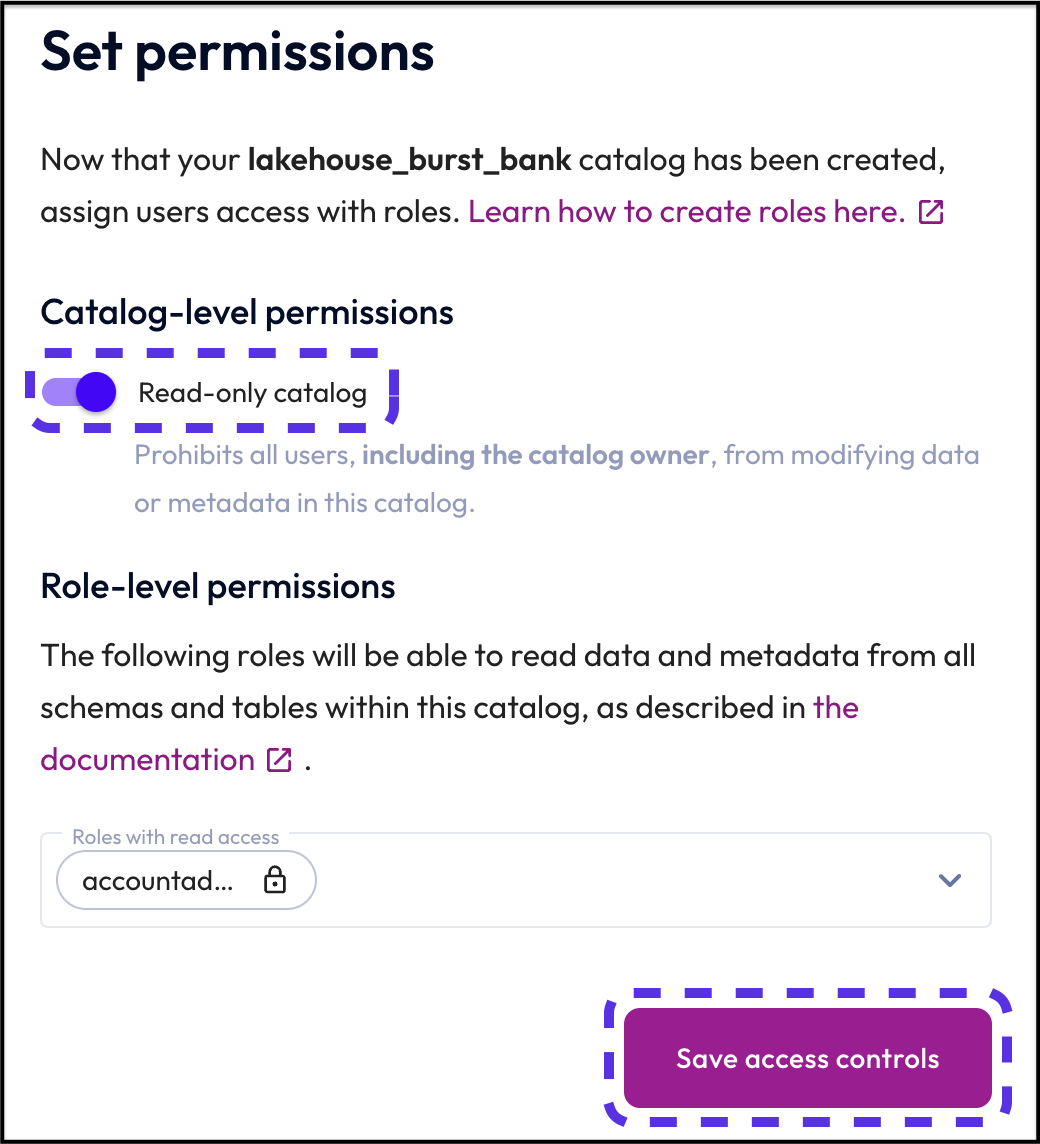
Step 6: Set permissions
Starburst Galaxy allows you to set permissions for every datasource. In this tutorial, we're going to set our access to the data lake to read-only and leave all other default settings in place.
- Select Read-only catalog.
- Click the Save access controls button.
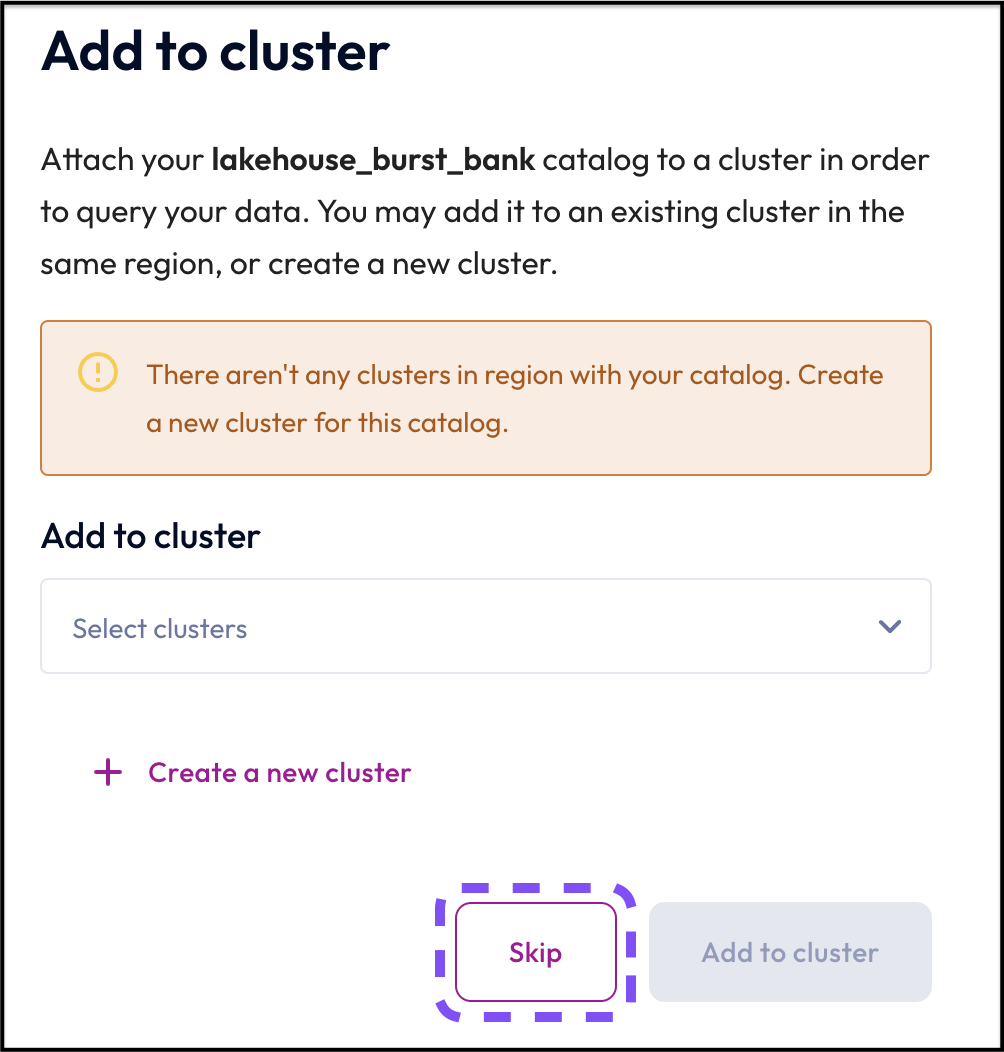
Step 7: Skip adding to a cluster
Starburst Galaxy allows you to add the catalog to a cluster at this point. For this tutorial, you're going to skip this stage and continue adding data sources then add them all to a cluster later.
- Click the Skip button.
Scenario
Burst Bank has customer information and customer account information stored in their data warehouse. In this section, you will use the PostgreSQL connector to access this data warehouse.
Step 1: Navigate to the Catalogs section of Starburst Galaxy
Connecting a data warehouse follows much the same process as connecting a data lake, both involve creating new catalogs to access the datasource.
- Using the navigation bar, select Data>>Catalogs.
- Click the Create catalog button.
Step 2: Select PostgreSQL datasource
Starburst Galaxy allows you to connect to a PostgreSQL data warehouse just like any other data source. PostgreSQL is listed in the Additional data sources section.
- Select the PostgreSQL tile.

Step 3: Configure the PostgreSQL catalog
Starburst Galaxy allows you to access PostgreSQL data sources on all three major cloud providers: AWS, Google Cloud Platform, and Azure. For this tutorial, you're going to use AWS.
- In the cloud provider section, select AWS.
- In the Catalog name field, input
postgresql_burst_bank. - In the Description field, type a meaningful description that will let you remember the purpose of this data source.

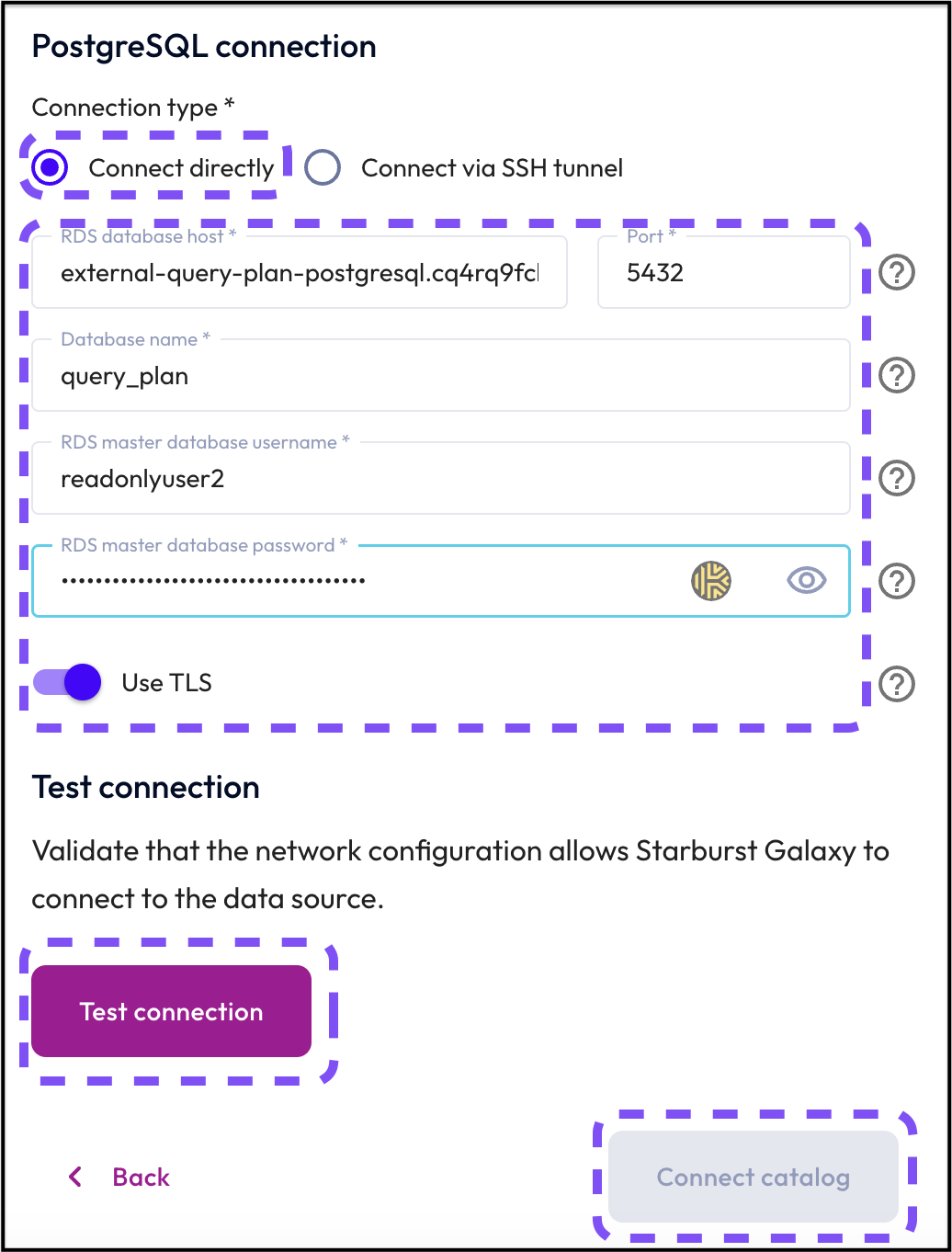
Step 4: Set the connection details
Now it's time to input the credentials that will allow Starburst Galaxy to connect to the PostgreSQL data warehouse.
- Select the Connect directly button.
- In the the RDS database host field, enter the following credentials:
external-query-plan-postgresql.cq4rq9fclcvt.us-east-1.rds.amazonaws.com - Keep port number as the default
5432. - In the Database name field, input
query_plan. - In the RDS master database user name field, input
readonlyuser2. - In the RDS master database password field, input the following credentials:
UPXT9jWPq*vG6UdeRg.h@QZKyJpMoiAQXL*n - Select Use TLS.
- Click the Test connection button.
- Confirm that you see the Hooray! You can now add this catalog to a cluster message.
- Click the Connect catalog button.
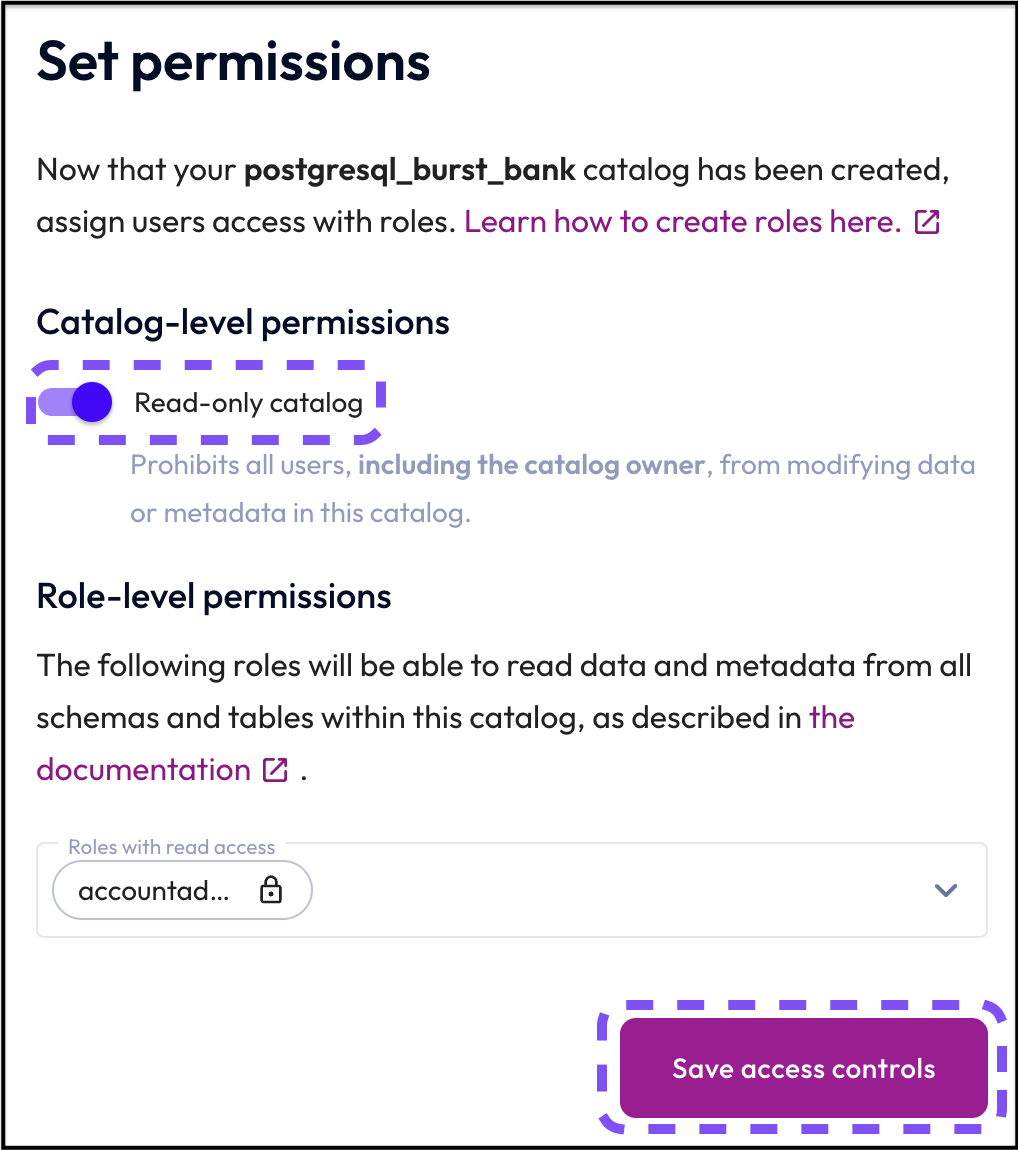
Step 5: Set permissions to read-only
Just like your data lake, for this tutorial you will only need read-only access. Starburst Galaxy lets you configure this as part of the setup.
- Select Read-only catalog.
- Click the Save access controls button.
Step 6: Skip adding to a cluster
You don't need to add the PostgreSQL data warehouse to a cluster yet. You'll connect both the data lake and data warehouse to the same cluster in the next section of this tutorial.
- Click the Skip button.
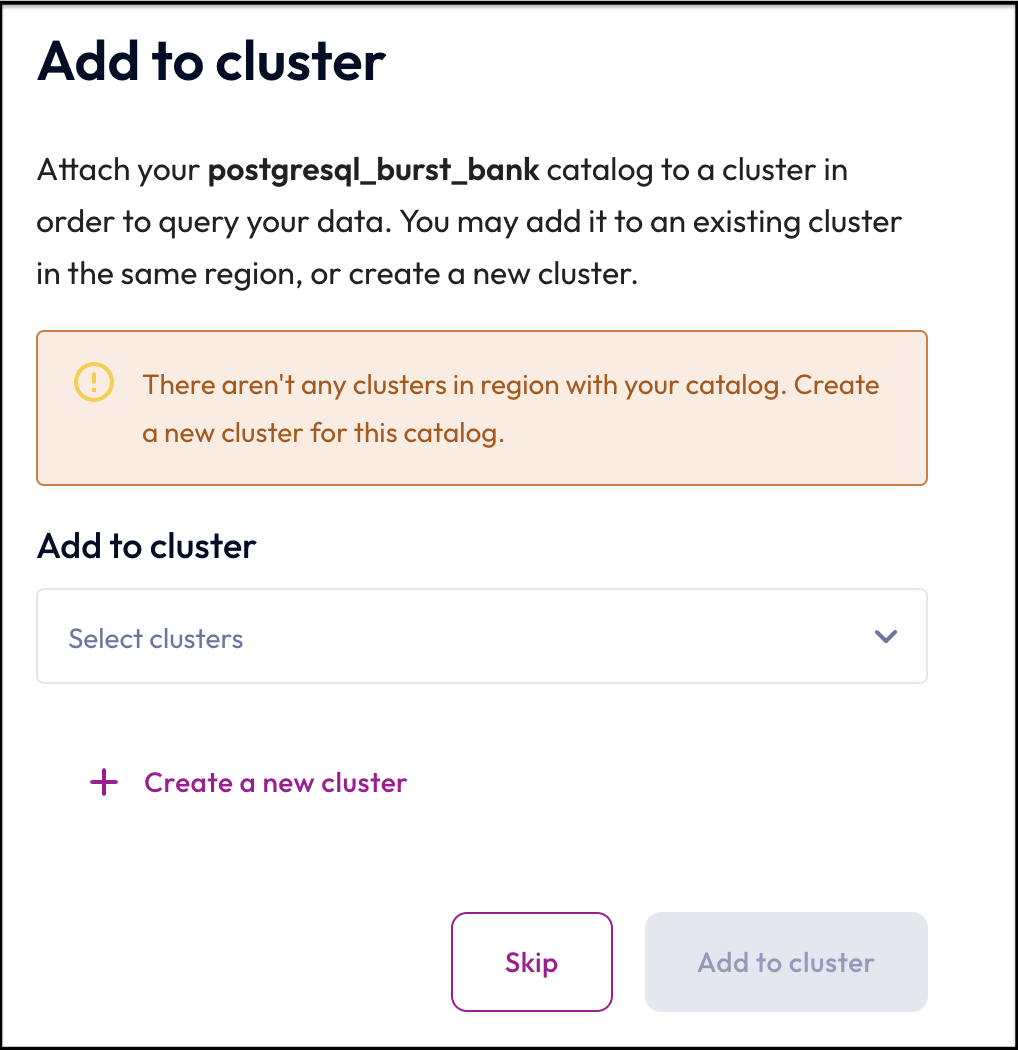
Scenario
All of Burst Bank's data sources are in AWS in the US East-1 (North Virginia) region. With Starburst Galaxy, the data sources and Starburst Galaxy cluster should be in the same cloud region to reduce cloud costs.
In this step, you will create a new cluster in US East-1 (North Virginia).
Step 1: Create new cluster
Begin by creating a new cluster
- In the navigation bar, click Admin>>Clusters.
- Click the Create cluster button.


Step 2: Name the cluster
Now it's time to name the cluster. This name should be something useful and indicative of its purpose and location.
- In the cluster name field, input
aws-us-east-1-free.

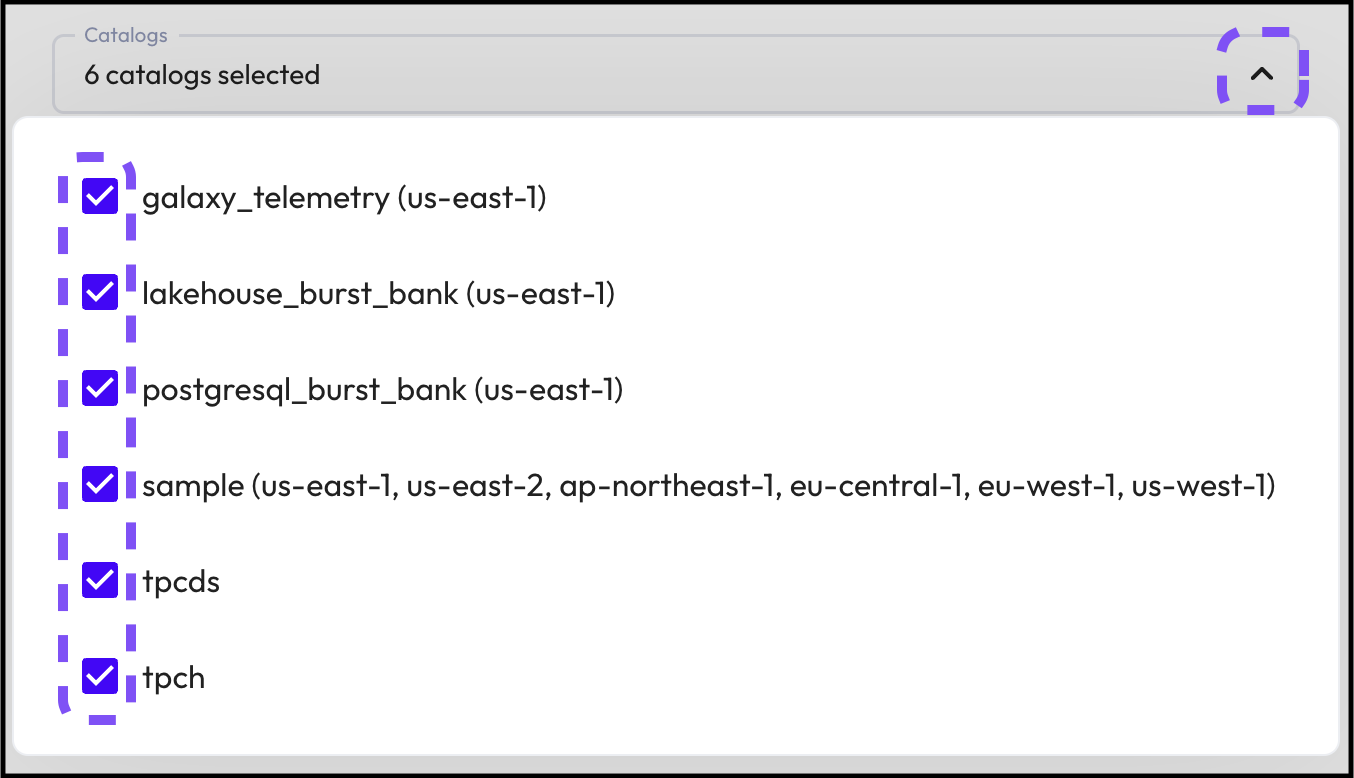
Step 3: Select catalogs in your cluster
Now you need to add all of the catalogs that you want associated with the new cluster.
In the case of the tutorial, you'll want to select all 5 catalogs.
- Select the Catalogs drop-down box.
- Select all of the catalogs available in the menu.
- Click outside of the menu to return to the previous screen .
Step 4: Add remaining cluster details
When you create a new cluster, you need to define certain key details.
- In the Cloud provider region field, select the default region (ex. US East N. Virginia). Note: Starburst Galaxy automatically determines the only region you can select based on the catalogs you select.
- In the Execution mode field, select Standard.
- In the Size field, select Free.
- In the Uptime field, select 30 Minutes.
- Leave all other fields as they are.
- Click the Create cluster button.

Step 5: Notice the cluster startup time
The cluster will now begin starting automatically. This takes a few minutes and you can watch the process update live.
- Notice how quickly the cluster starts up, even with all of the catalogs added. How long did yours take?


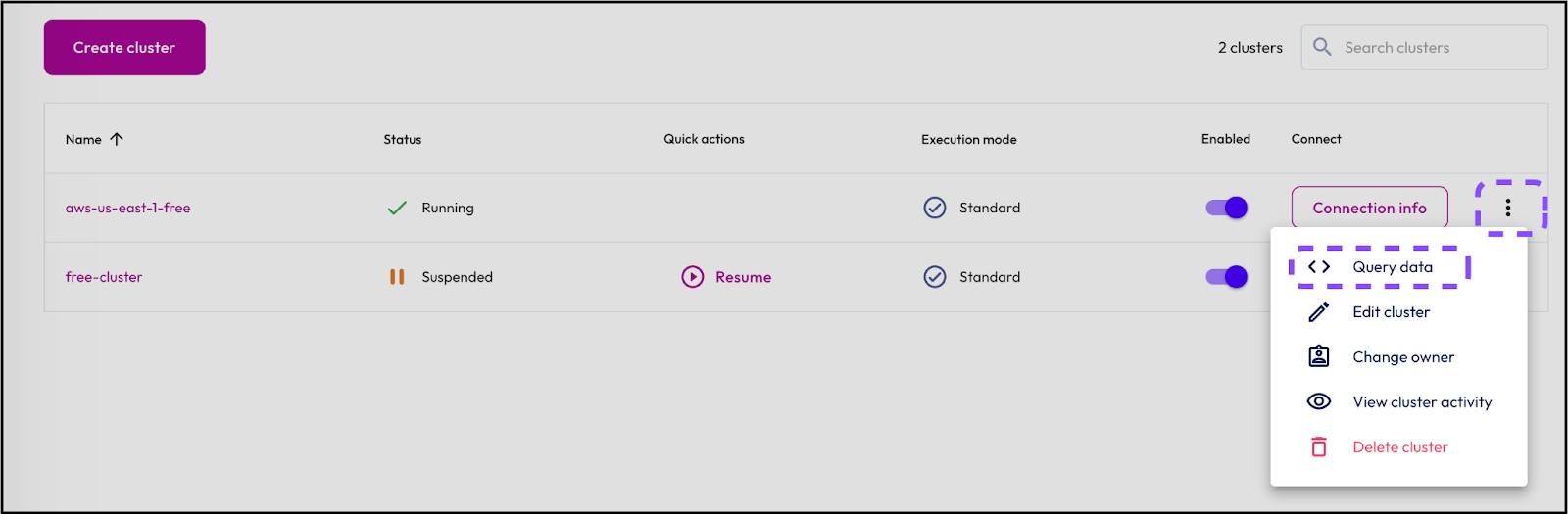
Step 6: Use a shortcut to the Query editor
Now it's time to return to the query editor. You can do this quickly using a shortcut.
- Click the ellipses to display the connection drop-down menu.
- Select Query data.
- Notice that Starburst Galaxy takes you to a new worksheet with your cluster already selected.
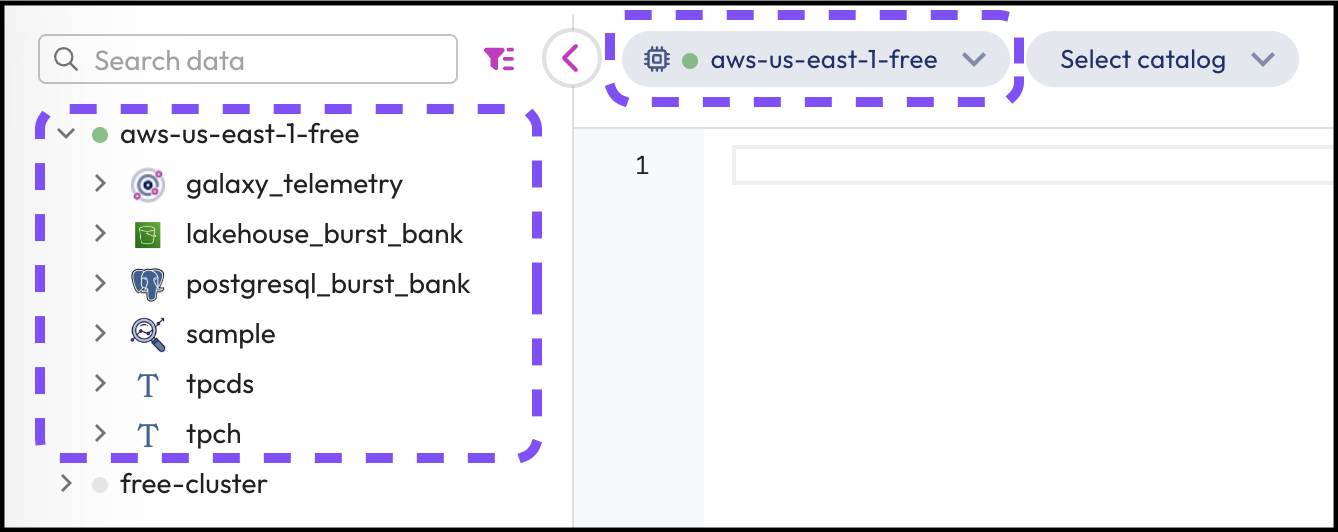
Step 7: Confirm that your catalogs are connected
It's always a good idea to confirm that new clusters have been created successfully, and that the correct number of catalogs has been added.
- Confirm that the new cluster
aws-us-east-1-freehas been added. Note that it has already been selected and is running. - Confirm that all 5 clusters have also been added.
Background
With Starburst Galaxy configured, you are now ready to produce the report for Burst Bank's risk department. Remember, they need a list of customers that have more than 3 delinquent payments in their history and a FICO score of less than 500.
Use SQL to join data warehouse and data lake
In this section, you will run a federated SQL statement across a data warehouse and a data lake to create the critical report the risk department needs.
Run the following SQL command to get the required information. Let's break it down to help understand what it's doing.
Breaking it down
The query returns several fields from different data sources. On the customer side, you're looking for:
- The customer's first name
- The customer's last name
- Their fico score
On the auto sales side, you're also returning some data, including:
- The auto loan ID
- The date that the loan was opened
- A list of any delinquent payments
Some of this data is in your lakehouse_burst_bank data lake and some of it is in your postgresql_burst_bank data warehouse. Returning results from two datasets requires a join, linking the customer ID and auto loan ID.
Finally, the delinquency of the account requires some conditional, boolean logic. You need to test whether the conditions for delinquency are true, and then if they are true, return the result if the delinquency is greater than 3.
These results are then aggregated using the GROUP BY command.
SELECT
c.first_name,
c.last_name,
c.fico,
a.auto_loan_id,
a.auto_loan_open_date,
count(al.delinquent_payment) as num_delinquent_payments
FROM
postgresql_burst_bank.burst_bank_with_stats.customer c
JOIN postgresql_burst_bank.burst_bank_with_stats.account
a on c.custkey = a.custkey
JOIN lakehouse_burst_bank.burst_bank_with_stats.auto_loan_payment
al on al.auto_loan_id = a.auto_loan_id
WHERE
al.delinquent_payment = 'Y'
and c.fico < 500
GROUP BY
a.auto_loan_id,
c.first_name,
c.last_name,
a.auto_loan_open_date,
c.fico
HAVING
count(al.delinquent_payment) > 3;Tutorial complete
Congratulations! You have reached the end of this tutorial, and the end of this stage of your journey.
Now that you've completed this tutorial, you should have a better understanding of just how easy it is to use Starburst Galaxy to connect different sources of data. Do you have data sources that you would like to connect to Starburst Galaxy? Check out our other tutorial offerings to see how easy it is to connect!
Continuous learning
At Starburst, we believe in continuous learning. This tutorial provides the foundation for further training available on this platform, and you can return to it as many times as you like. Future tutorials will make use of the concepts used here.
Next steps
Starburst has lots of other tutorials to help you get up and running quickly. Each one breaks down an individual problem and guides you to a solution using a step-by-step approach to learning.
Tutorials available
Visit the Tutorials section to view the full list of tutorials and keep moving forward on your journey!




