- Products
- -
- Starburst vs OSS Trino
- Why Icehouse with Starburst
- Open Data Lakehouse
- Data Mesh
- Artificial Intelligence
- ELT Data Processing
- Data Applications
- Data Migrations
- Data Products
- Pricing
- Customers
- -
- Learn
- -
- Partners
- -
- About
- -
- Login

- Start Free
Starburst Galaxy
Fully managed in the cloud
Starburst Enterprise
Self-managed anywhere
By Use Cases
By Industry
Documentation
Connect
Education
×
Blog
Resources
Pages
Documentation
Delivering Data Virtualization and Federation At Enterprise Scale
Performance, Scalability, Concurrency
Contact Us
Want to try Starburst? Have questions? We’re here to help.
Database federation and/or database virtualization was billed as the silver bullet that could alleviate much of the pain associated with data sprawl. Unfortunately, none of the early data federation systems ever lived up to their promise. It turned out that building them was much harder than anybody expected. Facing these challenges, Starburst is excited to offer an cutting-edge solution which will deliver on the original promise of data federation with a new, evolved architecture.
Single point of access to all data

We know the problem all too well
Challenges with legacy data virtualization:
- Creates more vendor lock in.
- Must leverage MPP engines (Spark, Hive, Impala, Trino) for high performance data lake queries.
- Federation servers create performance and concurrency bottlenecks
- Requires integration for fast parallel execution against data lakes
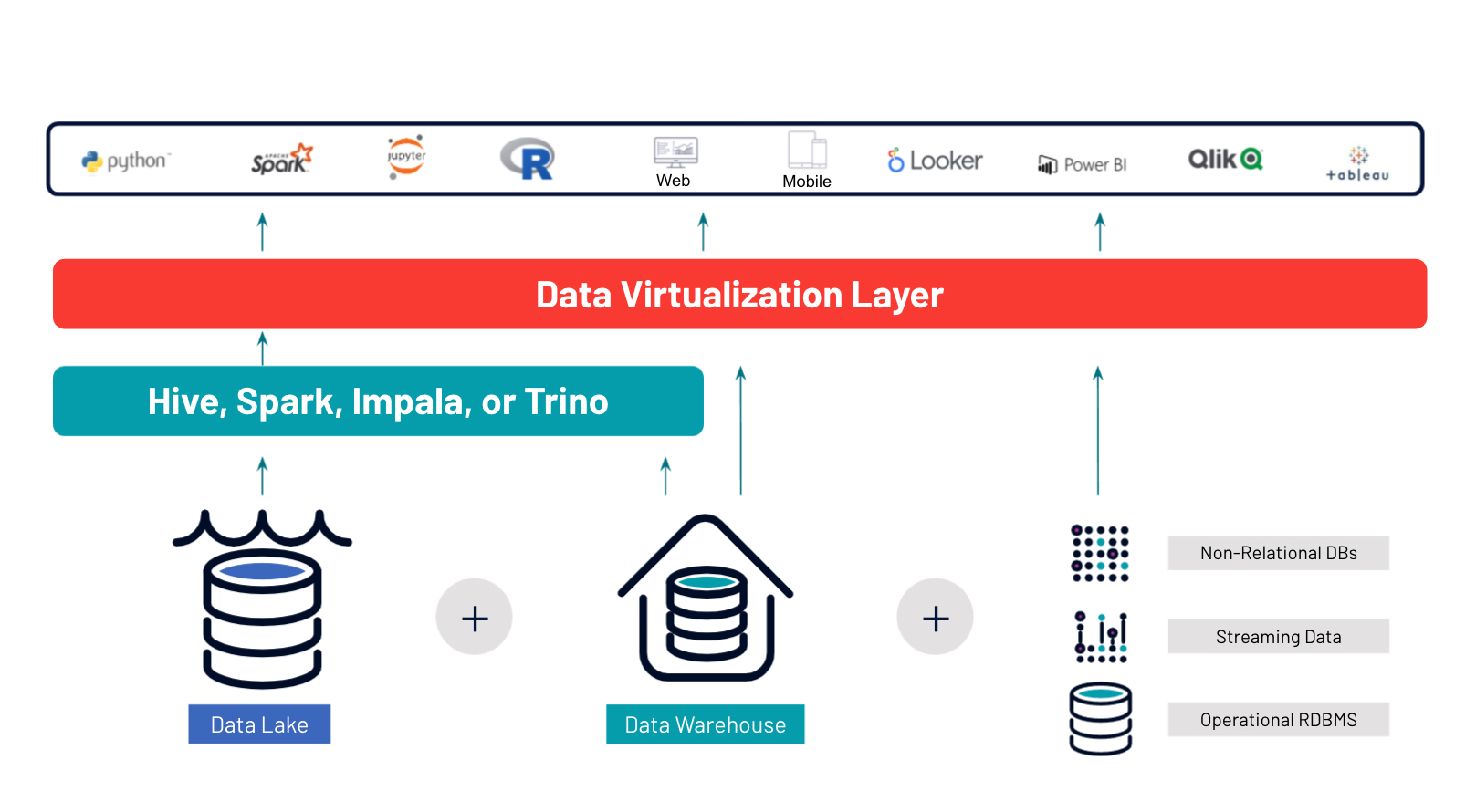
Advantages with Starburst:
- 10 – 100x faster query performance over other MPP engines
- 1/3rd the compute resources vs Hive, Spark & Impala
- Zero reliance on source data systems to perform joins but have the flexibility to pushdown where it makes sense to optimize performance.
- ANSI SQL standard no matter where the data originates
- Proven at 1000+ node and 100+PB scale
- Performant ground to cloud, multi-cloud, and multi-region analytics on data lakes with Starburst Stargate
- No vendor lock-in to underlying data sources. Provides storage optionality
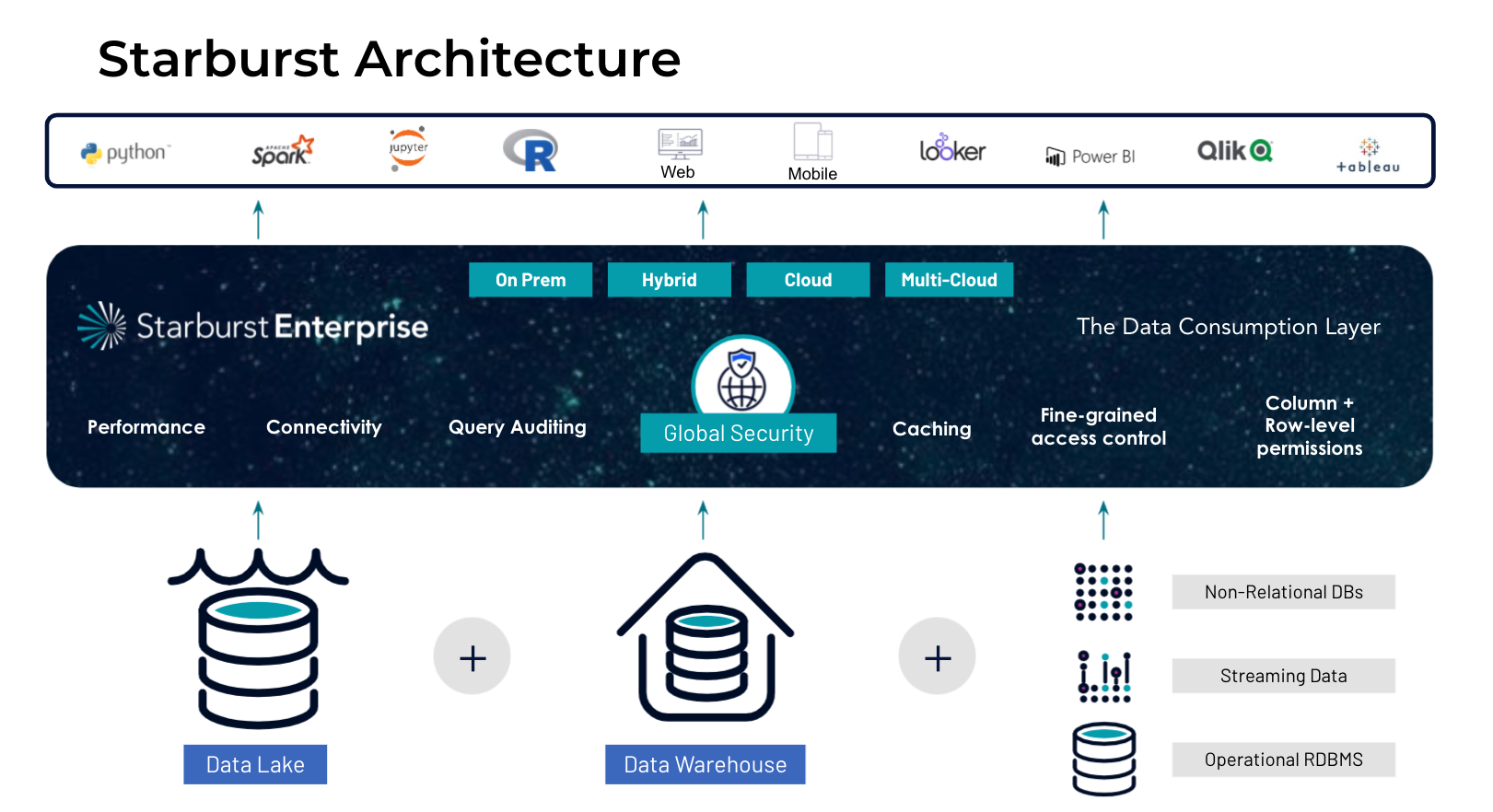
Compare the features
| Connectivity |
- Native connectivity to most enterprise systems, requires integration for object storage - Lack of native parallel processing connectors - Single point of access - but no native MPP capabilities for data lakes and object storage |
- Certified JDBC and ODBC driver - 40+ supported enterprise connectors - High performance parallel connectors for Oracle, Teradata, Snowflake and more |
| Concurrency | - Limited level of concurrency |
- High concurrency from terabytes to exabytes - Query data from disparate sources using SQL |
| Scalability |
- Scales vertically into a single node, preventing efficient scale - Tied to the querying solutions of existing database without flexibility |
- Unlimited scalability - Autoscaling with graceful scaledown - Simplified deployment anywhere - High availability |
| Optimization | - Cost-based optimizer available | - Cost-Based Optimizer for federated queries |
| Latency | - Extremely inefficient and resource intensive for cross cloud data lakes | - Powerful Stargate connector enables global cross-cloud analytics at MPP scale |
Starburst customer results
Leading Telecom Provider in North America chose Starburst for data virtualization and federation
- Expected reduction in customer churn and improved NPS scores by delivering faster actionable insights on 500,000 daily Care calls, surveys, etc
- Queries that took 2 hours now take 9 minutes
- 61% TCO savings in year 1 by implementing Starburst
- Care use case will be foundational to Semantic Layer, delivering more positive outcomes as supply chain, marketing, and other line of businesses are onboarded
- Considered other data virtualization tools but they could not meet MPP scale that required open source engine, such as Trino



A single point of access to all your data





© Starburst Data, Inc. Starburst and Starburst Data are registered trademarks of Starburst Data, Inc. All rights reserved. Presto®, the Presto logo, Delta Lake, and the Delta Lake logo are trademarks of LF Projects, LLC