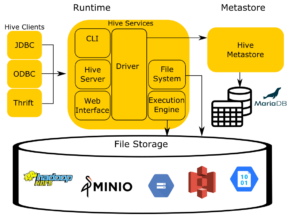


What is Apache Impala used for?
Impala uses Hive’s variation of SQL syntax, as well as the Hadoop Distributed File System (HDFS), data and file formats, metadata, and other features of the Hadoop framework. This consistency makes it easier to adopt Impala within a Hadoop ecosystem for a variety of use cases.
For example, Impala provides business intelligence analysts with a better data warehouse experience with lower latency than Hive can deliver. Similarly, Impala supports the iterative exploration to develop big data science projects.
In addition, Impala reduces the cost, storage, and overhead of preparing data for large, complex projects since data formats don’t have to be converted and processing can occur on local data nodes without moving massive datasets.
Other SQL query engines: Impala vs Spark vs Trino vs Hive
When developed in 2012, Impala’s relatively low latency offered a compelling alternative for real-time and interactive analytics applications in the Hadoop ecosystem. Today, organizations have other frameworks to consider that may prove better-suited for their big data initiatives.
Trino vs Impala
Trino is an open-source MPP SQL query engine that works with Hadoop and modern data lake platforms.
Accessibility: Based on ANSI-standard SQL, Trino requires less of a learning curve than Impala. Expert users can use the SQL they already know to, for example, include SQL statements in Python code for machine learning projects. Likewise, analysts’ business intelligence tools can query data sources efficiently. Impala’s reliance on HiveQL limits its use to those with relatively specialized skills.
Federation: Trino connectors allow queries to pull structured and unstructured data from disparate enterprise data sources without consolidating everything in a central repository. By contrast, Impala can only access data stored in HDFS.
Data management: Trino reduces end-user demands on data teams’ limited resources and frees engineers to work on higher-value tasks. Thanks to Trino’s standard SQL, engineers can develop easier-to-maintain data pipelines — and often eliminate pipelines altogether.
Apache Spark vs. Apache Impala
Both Spark and Impala live under the Apache Software Foundation’s umbrella. The two frameworks play complementary roles within a Hadoop-based architecture.
Processing priorities: Impala’s primary role is to provide interactive query capabilities. This enables a data warehouse experience on HDFS and avoids implementing a proprietary data warehouse platform. Apache Spark is better suited for other processing tasks like handling streaming data or running batch processes.
Flexibility: Impala is limited to HiveQL to support SQL-like interactive queries. Data engineers can write Spark-based data processing code using Python, Java, and other languages.
Technologies: Impala’s tight integration with HDFS, while Spark is also compatible with Parquet, Avro, and other data storage technologies.
Related reading: Why is Trino faster than Spark?
Apache Impala vs Apache Hive
Hive is a query engine designed to address the limitations of Hadoop’s MapReduce programming model. Based on Java, MapReduce requires a specialized set of skills to use effectively — skills most users don’t have.
Hive abstracts MapReduce’s complexity by providing an SQL-like interface, HiveQL, for writing queries. Hive then translates each query statement into the appropriate MapReduce code and returns the results. Although Hive made querying Hadoop data storage easier, HiveQL is not pure SQL and imposes a learning curve on anyone needing to use it. Hive also has inherent performance limits since HiveQL queries are actually MapReduce queries with extra steps.
Addressing the latency impacts that Hive imposes when querying large data sets was one of the drivers behind Impala’s development. Unlike Hive, an overlay on the MapReduce compute engine, Impala is a self-contained SQL compute engine. It bypasses MapReduce entirely to query data faster and improve scalability.
However, the Impala project also prioritized tight integration with Hadoop. That Impala supports Hive’s JDBC/ODBC driver, table metadata, and other features makes the compute engine’s integration with Hadoop architectures as seamless as possible. However, it also means that Impala relies on the non-standard SQL syntax of HiveQL and thus limits its accessibility to the full range of end-users.
How Starburst helps with Apache Hive and Impala
Starburst has played different roles for companies that use Hive and Impala, from optimizing existing Hadoop infrastructures to replacing Hadoop entirely with an open data lakehouse.
Data modernization
Starburst supports modern table and file formats to become the compute engine of a modern data lakehouse analytics system. Based on the massively parallel Trino SQL query engine, Starburst allows companies to achieve the cost savings of cloud object storage while getting better performance and latency than conventional data warehouses. Thanks to ANSI-standard SQL, query generation is accessible to anyone with SQL skills or SQL-compliant applications.
Hadoop migration
Starburst can help companies migrate their on-premises HDFS architectures to the cloud. Over fifty connectors let Starburst federate enterprise data sources and make them accessible from a single interface. Virtualizing the on-premises data system lets the migration process happen seamlessly and transparently without impacting business users.
Hadoop optimization
Companies that prefer to keep their Hadoop infrastructure replace Hive and Impala to optimize query performance. Starburst uses Trino to replace the Hive runtime while retaining its other components like the Metastore. With the implementation of the Trino Hive connector, Starburst delivers fast queries on Hadoop platforms with higher concurrency and lower latency than Hive or Impala can ever achieve.
Starburst is a more cost-efficient, accessible, and performant alternative to Hive, Impala, and even Spark — especially as data continues to scale. Our customers have seen a tenfold performance improvement and a two-thirds reduction in infrastructure costs by adopting Starburst’s analytics solution. A large US bank used Starburst to replace Impala, reducing their time to insight for critical risk models by 96%. Replacing Spark let the bank eliminate ETL pipelines for joining Oracle and HDFS data with significant savings.




