


There are three schemas used in data warehouses: star schema, snowflake schema, and galaxy schema — all of which promote fast and efficient querying of large data sets.
The descriptions below outline how each of these schemas functions in practice and explore them with a simple example of credit card payments data from Burst Bank.
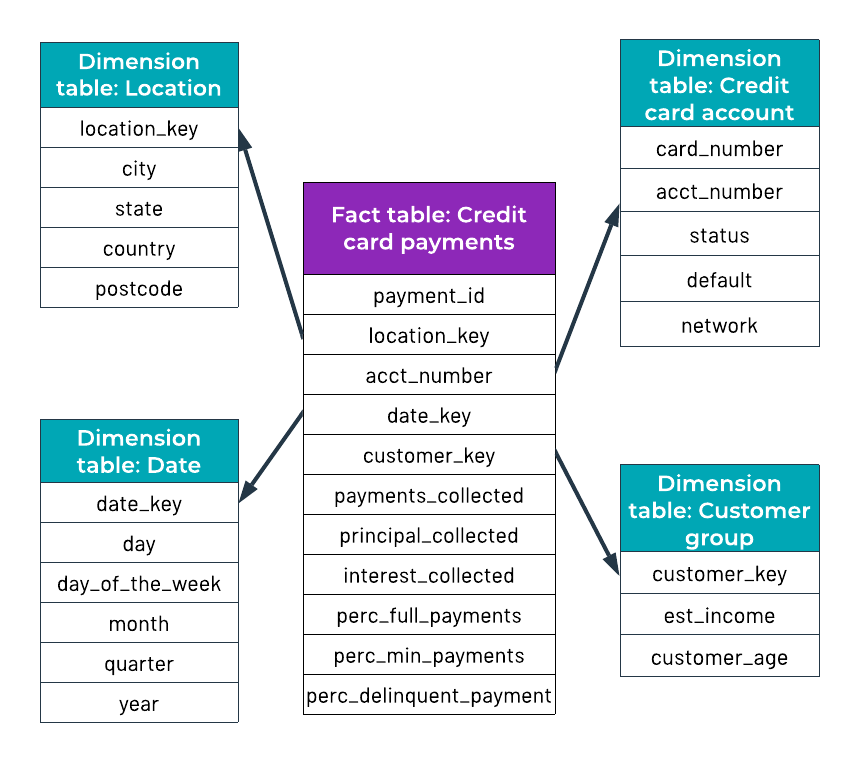
Star schema example
In the figure below, the credit card payments fact table is related to four dimensions: location, date, credit card account, and customer group. Customer group includes estimated income and age. The fact table also includes many aggregate measures of data credit card payment data, such as the percent of full payments collected and the percent of minimum payments collected. Business analysts can use these measures to answer the types of questions that will help their company make business decisions. An example of a question that they could answer with this data is: Are customers over the age of 40 more likely than customers under 40 to make full payments?
What is a Snowflake schema?
In a snowflake schema, each dimension connects to a central fact table. Some of the dimension tables are normalized so that they have sub-dimensions. This normalization reduces some of the data redundancy and makes it easier to maintain and store data. However, this comes at the cost of less efficient queries because each query requires more tables to be joined together.
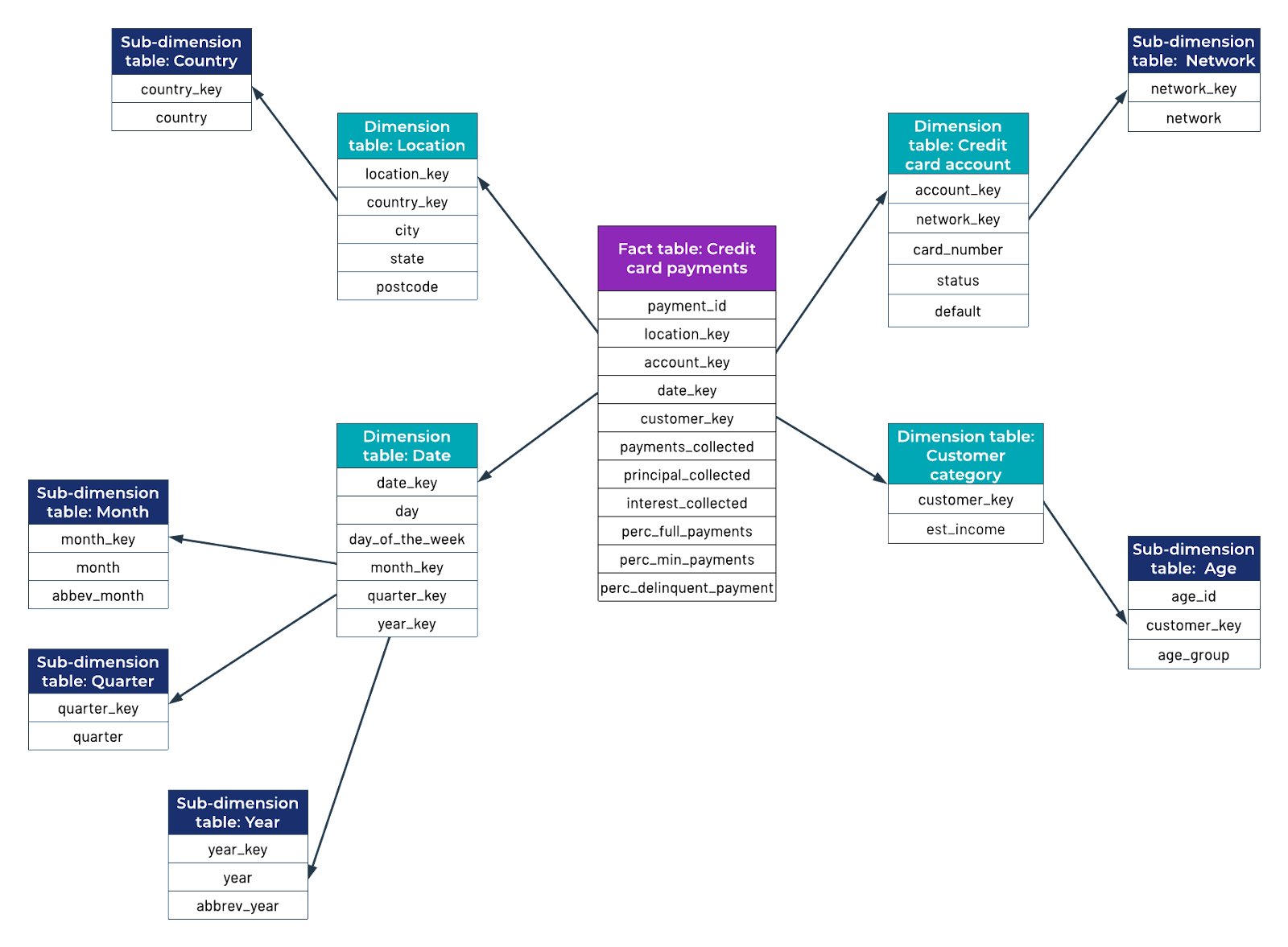
Snowflake schema example
In the figure below, the credit card payments fact table is related to the same dimensions as in the star schema example. However, each dimension table is also connected to one or more sub-dimension tables. For example, the date dimension table has sub-dimensions for month, quarter, and year. The sub-dimension tables for month and year include abbreviations that business analysts might use to look up month or year from the database.
What is a Galaxy schema?
Galaxy schema, also known as the fact constellation schema, has several fact tables that each hold the keys and aggregate data for specific parts of a business. Each fact table can connect to some of the same dimension tables, but each also connects to some dimension tables not connected to other fact tables. In this design, dimension tables cannot have sub-dimensions. This schema results in slower queries than both the star and snowflake schemas because its complexity means more tables must be joined when the data is queried. However, galaxy schemas can be useful for extremely complex data because they lower data redundancy by normalizing the data and mapping data to multiple fact tables.
Galaxy schema example
In the figure below, a fact table that contains aggregated data about the merchant at which customers made purchases has been added to Burst Bank’s data warehouse. The merchant fact table is connected to a dimension table that describes merchants by the category of goods or services they sell.

How Starburst helps with complex data warehouse setups
Starburst’s distributed query engine, based on open-source Trino is particularly beneficial in the following ways:
Distributed Query Processing: Distribute queries across multiple nodes enables it to handle large datasets and complex join operations typical in these schemas.
Connectors to Various Data Sources: Connect to a wide range of data sources(including: AWS S3, GCS, Azure data lake) which is particularly useful in environments where data is spread across different systems and formats, a common scenario in complex data warehousing setups.
Deploy in various environments: Including cloud platforms, on-premises systems, and hybrid setups. This flexibility is crucial for businesses with diverse data infrastructure, often seen with different warehousing schemas.
Scalability: As data volume grows, which is often the case in data warehousing, performance remains consistent, regardless of the complexity of the data schema in use.




