
Data lakes are powerful resources for organizations, offering a centralized repository for all your data at scale. However, navigating through vast amounts of data to find what you need can be challenging without the right setup. A challenge with data lakes is managing raw data stored without any oversight of the contents.

“The main challenge with a data lake architecture is that raw data is stored with no oversight of the contents” AWS, What is a data lake?
Transforming Data Lakes into Data Lakehouses
The solution? Transform your traditional data lake into a data lakehouse. A data lakehouse converges the principles of a data lake and a data lakehouse by adding together to create the best of both worlds and leverage those data warehouse-like capabilities on a data lake.
AWS data lakehouse: Why Choose Starburst?
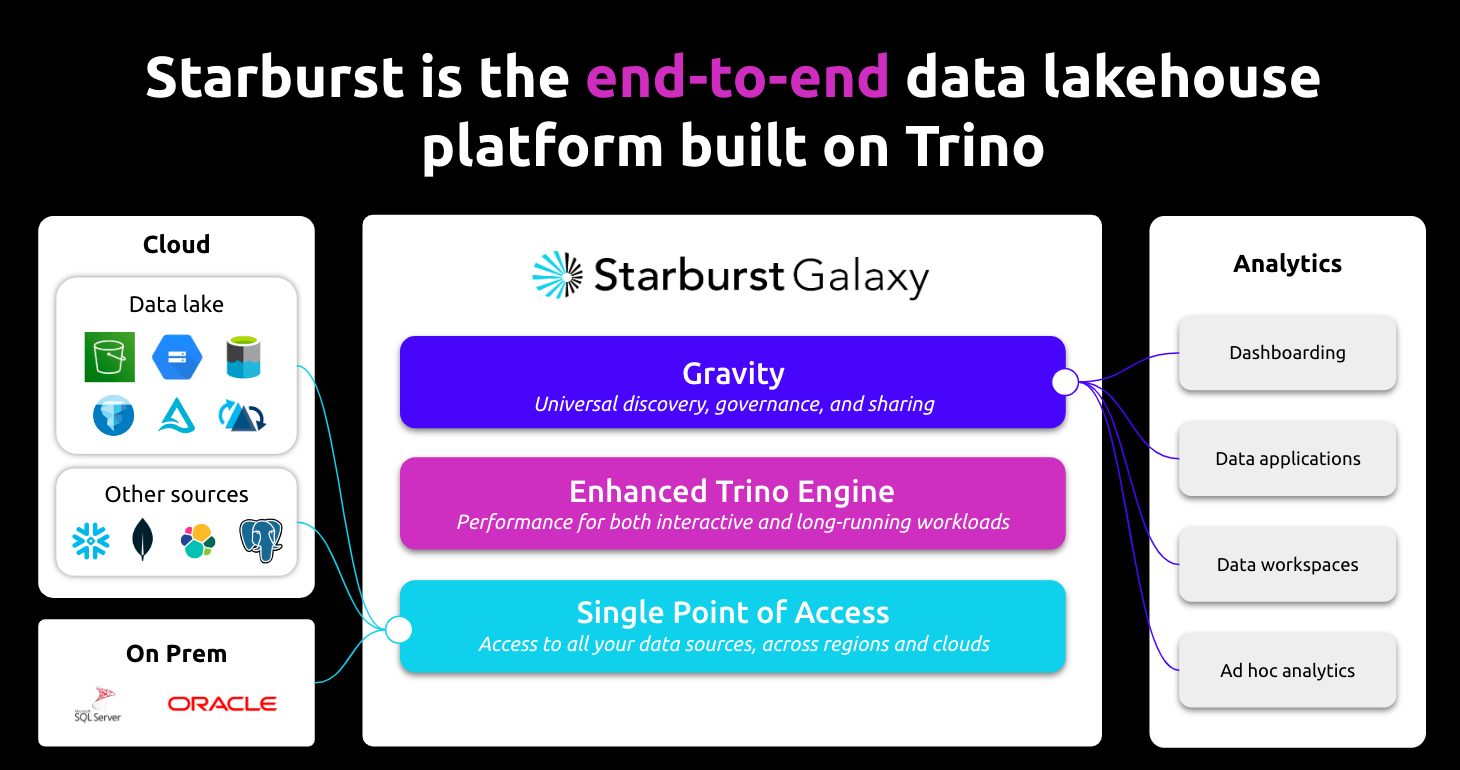
Starburst Galaxy offers three benefits for building a AWS data lakehouse:
- Flexibility in Query Execution: It supports both interactive and long-running queries, essential for diverse data needs.
- Compatibility with Modern Data Formats: It integrates seamlessly with formats like Apache Iceberg, Delta Lake, and Hudi.
- Integration with AWS: Seamless compatibility with AWS services enhances its functionality and ease of use.
How To Migrate Queries From Amazon Athena To Starburst Galaxy
3 Key Components of a Successful AWS Data Lakehouse

- Utilizing OpenTable Formats: Formats like Iceberg, Delta Lake, and Hudi offer data warehouse functionalities such as merging, updating, and transaction management, which are crucial for efficient data handling.
- Implementing Native Security: Starburst Galaxy allows for detailed access control, down to specific tables or storage locations, ensuring that users have the right access for their roles.
- Building a Structured Reporting System: Organizing data into 3 layers—Land, Structure, and Consume—helps manage the data lifecycle from raw input to analysis-ready information.
- Land layer: Raw data that’s landed into S3.
- Structure layer: Which is cleaned and optimized.
- Consume layer: Which is actually ready to be queried by the end users.
AWS data lakehouse demo with Starburst Galaxy
In our demo below, we’ll showcase how Starburst Galaxy manages these open table formats, integrates with identity providers like Okta, Azure AD, and Google Workspace, and allows for the customization of access and roles. We’ll also highlight how to leverage Starburst Galaxy to maximize the potential of your AWS data lakehouse.
Building Reporting Structures on S3 using Starburst Galaxy and Apache Iceberg
Using Apache Iceberg, AWS S3, and AWS Glue to manage a data lakehouse architecture








