
Even prior to the 21st century, data-driven decision-making implied that the mere presence of data in a data-driven economy was all that’s required as an innovation strategy and to make better decisions. However, this data collection approach and use of data hasn’t provided organizations the data investment returns they thought it would for a number of reasons.
Since then, the world has moved on to an AI strategy and focus on machine learning, but without the right data strategy you can’t “do” AI. Data is the lifeblood of artificial intelligence. AI systems learn and make decisions based on the data they are trained on. Without high-quality, representative, well-organized big data, AI models cannot function effectively. Whether you’re in health care, finance, or retail, data management is essential for collecting, storing, and maintaining the data needed to train and operate AI systems.
What is data-driven innovation(DDI)? Why is data the key to innovation?
Data-driven innovation (DDI) is a strategic approach that leverages the power of data (whether its big data or small data) to facilitate better decision-making and drive advancements within organizations. It recognizes that having access to data alone is insufficient for achieving optimal results. Instead, it emphasizes the need for high-quality, well-organized data and a carefully planned data management strategy and business strategy, and how ultimately data analytics support an organization’s business model.
Gartner produced a research report on this topic a few years ago: The Practical Logical Data Warehouse and the data management infrastructure model where they presented a simple framework for thinking about the types of questions our consumers were asking and where that data was coming from, and we have extended that framework in this blog.
How can data be used to innovate?
In this blog we take a closer look at how the ideas of known and unknown data and known and unknown questions impact our data ecosystem as we expand and extend the data management infrastructure model.
The legacy data stack: Focusing on the known knowns
For the past 30 years, organizations have been centralizing data to support management decisions — focusing on known data with a clear model, and well-understood questions. In other words, this data ecosystem is designed to use known data to answer known questions.
The data architecture to support this approach typically begins with a process of business analysis to understand what questions we want to answer. Then, we step through the process of creating a conceptual, logical and ultimately a physical data model to answer these questions and choose a technology platform on which to build this data architecture, this is often known as a data warehouse.
Building the data warehouse consists of activities such as implementing data models via various ETL / ELT or Change data capture processes, and creating data pipelines from source systems to populate the target data model. This is the basis of data warehousing and also the very similar data lakehouse architecture approach.
Up until very recently, the creation, development, and maintenance of the data warehouse or data lakehouse was performed by a central data team. This central team is typically either an expensive standing army or an overworked, overtasked, and overwhelmed team, either case leads to underwhelming business value, whether that’s due to delayed projects, delayed business outcomes or slowed innovation processes.
In the end, answering predetermined questions is based on a centralized and well-articulated data model, but fails to enable data exploration, experimentation and the evolution of the data-driven business strategy. These failures only get worse with time as more data needs to be integrated and the platform becomes more fragile to change. Ultimately this fails to deliver timely and competitive business results and we have seen examples of this where onboarding new data sources has taken months rather than days.
As we’ve seen, providing known data to answer known questions can be done using many well-known data architectures, but that’s only part of the story.
“We can discover, access, and analyze data in our data lake with our preferred tools, and leverage it for business intelligence and data science. This streamlined workflow helps our executives make the right decisions on time, and fosters innovation through machine learning.” Alberto Miorin, Engineering Lead, Zalando
Data-driven innovation framework
Before we move on let’s define some terminology that will be used throughout the rest of this blog.
Known data
Known data is data that is familiar to teams within the organization. Typically known data has had one or more of the following activities performed on it: centralized, integrated, modeled or aggregated.
Known questions
Known questions are questions that have previously been considered and for which data is likely to have already been known, as above.
Unknown data
Unknown data exists either within or outside the organization, and which hasn’t previously been known. Unknown data likely contains the makings of business value that hasn’t been discovered yet, and could be unique to the business.
Unknown questions
Unknown questions are questions that have yet to be asked, new experimental analyses or new exploratory scenarios. Unknown questions support innovation and will potentially lead to significant competitive differentiation in your respective industry.
4 Quadrants
Together, the terms comprise the existing Gartner data management infrastructure model.
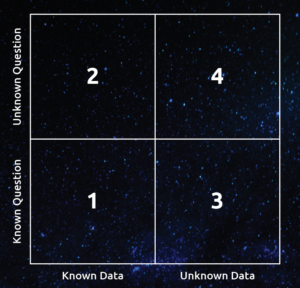
However, to truly become data-driven means providing venues for both known data and unknown data, and enabling known questions and unknown questions to be asked of that data.
Therefore, below we extend the existing model into known and unknown data and questions into four business decision-making scenarios that support business decision making:
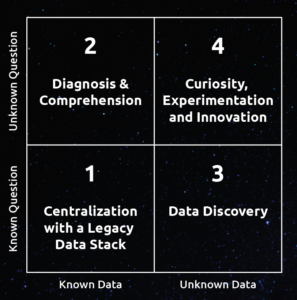
Let’s take a closer look at each of the quadrants.
Quadrant 1: Known data and known question
Examples of known data, known question
- Known questions: Who are my most profitable customers?
- Known data: Data that’s already modeled in a warehouse or lakehouse
Centralization with a Legacy Data Stack

The legacy data stack — focused on clear and well-understood data and analyses — addresses quadrant 1, with known data and known questions.
This is the foundational core to a data strategy, and is the first step on the journey of data maturity. This is often a centralized data architecture with a clear set of tools and users.
The initial design of most systems to support business decision-making have been optimized for known data and known questions. There is centralized data that downstream consumers clearly understand, hopefully focused on the most pressing questions which generate the greatest return on investment in data and technology.
Once an organization has this platform in place and the data available it may spur further, more diagnostic or unknown questions, leading us to the next quadrant.
Quadrant 2: Known data and unknown questions
Examples of known data, unknown question
- Unknown question: What are the characteristics of my most profitable customers?
- Known data: data that’s already modeled in a warehouse or lakehouse
Understanding and investigating

While the legacy data stack is finely tuned for well-defined data and analytics, it can also serve the case of new analytics on top of the well-defined data. This is the case with Quadrant 2, or the known data and unknown questions.
With a clearly documented data model and accessible data, asking new questions which require no new or unknown data can be fairly straightforward.
In this scenario we have a good understanding of the data that we have available, even if we do not know the sorts of questions that will be asked either today or in the future.
One approach to cater for this requirement is the creation of data marts and cubes, which have provided a way for data producers to present data in a well-defined way for downstream consumption.
In a data lake, this is particularly important because the ratio of known data to unknown data can be quite low. By pre-aggregating or pre-integrating data into discrete and comprehensible datasets, when the time comes to ask a new question the data will be readily available and can be used to produce new analyses.
These data ecosystems for known data typically have an efficiently integrated data model that reflects business logic from across the operation. However, the main challenge with a system so streamlined toward known data is that the introduction of new data or new analytics needs can be quite taxing.
Moving on to quadrant 3, dealing with new, unknown data presents materially greater challenges in terms of time and effort.
Quadrant 3: Unknown data, known questions
Examples of unknown data and known questions
- Known question: What’s the behavior of my most profitable customer?
- Unknown data: Data that hasn’t been centralized and modeled.
Data Discovery, finding new data to answer known questions
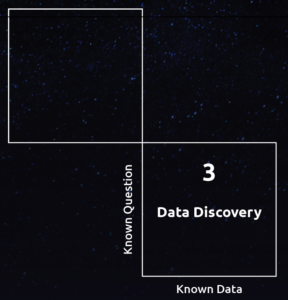
Legacy data stacks are tailor-made for centralized, clearly modeled data.
However, in the ever-changing and dynamic world of modern business there is no guarantee that data will remain unchanged, instead, new varieties of data are constantly being produced.
In a data lake, there is a vast amount of data, some of which has great potential, but which is unused — often this is called dark data — in a recent BCG study, they’ve found that 50% of data that companies store is dark data.
When there are known analyses that require unknown or previously undiscovered data, or the data is new to the organization, this is represented in quadrant 3: unknown data, known questions.
Ideally there will be some sort of enterprise-wide data catalog which can help would-be consumers uncover the data they need, and this is often a good solution, but the reality here is that the data is often unknown and yet to be cataloged.
Once the data has been determined to exist the real race begins, time is critical for competitive advantage but, in a legacy data stack world to make the data available requires
building a pipeline to centralize and model the data before it can be consumed. This causes a significant delay in any analysis.
The ideal situation here would be for users to easily be able to discover new data – global search capabilities are very important in a catalog for just this reason. Furthermore, the data must be secure and easily understandable by downstream consumers so they don’t go astray in their analyses.
While the legacy data stack cannot provide this capability, there are a slew of new tools which can allow for true data discovery, leading to truly new and exciting analytics and business value. Data discovery can also be very valuable when we are considering new or unknown questions.
Quadrant 4: Unknown data, unknown questions
Examples of unknown data and unknown questions
- Unknown question: What’s the least investment we need to make to keep a profitable customer?
- Unknown data: Data that hasn’t been centralized and modeled.
Curiosity, experimentation, and innovation

The final quadrant represents true and potentially unique business value in the form of experimentation, and is in some ways the mark of a mature data strategy. The ability to discover new data and ask/answer new questions with that data in a secure, reliable way, whilst complying with data sovereignty and gravity concerns is paramount to extracting the true business value of data.
With unknown data and unknown questions, consumers are free to innovate and experiment with data, searching for new and exciting ways to realize business value via data analytics.
In my informal discussions with CDOs, organizations value this experimental work, and regularly allocate 10-20% of their team’s time to create new value-based data activities and test out ideas. Giving teams the freedom to be curious with data in a search for new value is critical to uncovering new and creative solutions to business goals.
In the world of unknown data and unknown questions, data virtualization and federation technologies are particularly useful. These technologies enable the user to discover pertinent data and gain access to it quickly, and is especially useful in a data science capacity.
Legacy data stack components rely on the data to be pre-defined and modeled, the antithesis of true innovation and exploration that is required for an actual mature data ecosystem.
The true mark of maturity for a data ecosystem is the ability to do what we call “hypothesis-driven development,” where both known and unknown data can be used to answer known questions and explore unknown questions.
How hypothesis-driven development relates to data analytics?
Hypothesis-driven development is the concept of developing a new hypothesis, setting out what the success of that hypothesis looks like, then testing the hypothesis against those tests and analyzing the results in a tight iterative loop.
If we apply this to data analytics it becomes the process of developing new and unknown questions with associated metrics of success, testing the answers to the question which requires either known data or new / unknown data or a combination, and then analyzing the results, and if the results prove that the hypothesis has value then the outcome could perhaps become a data product.
For data teams to achieve this process including discovering new data and innovating on new business value obtained from that data, the data architecture needs to be flexible enough to handle both known and unknown data and analytics.The following case study illustrates this:
What are data-driven innovation examples? | Example case study
Let’s consider a marketing analyst who has an innovative idea for predicting customer churn. She has a new question that is going to require known and unknown data. The analyst does not know what data is available or where the new data might reside.
The analyst has an opportunity to impact his business with her innovative idea.
There are two scenarios:
The first scenario with a centralized approach leads the analyst into the cycle of doom, which you can read more about it, here.
We’ll focus on the second scenario where she can be independent and autonomous, failing fast, and iterate through unknown data and unknown questions in quadrant 4.
The analyst needs to discover and test new data quickly and securely:
- She doesn’t have time to wait for a migration or wait for a new traditional data pipeline
- She isn’t in a position to point to which data sets she needs
- She is in a true experimentation mode
This is where Starburst provides tremendous value creation allowing the analyst to experiment and innovate with speed, to create a competitive market advantage.
![]()
After a degree of experimentation, the analyst will generate known data that supports a known question. She will use this insight to improve customer churn analytics and others will be able to use this known data to answer their own known or unknown questions.
Enter the data product
To promote reuse, consistency and accountability for known data, organizations should move from quadrant 4 to quadrant 1 by creating a data product to make this data available to the rest of the organization.
From the example above, we see two obvious implementation approaches:
- Continue to use the dataset definition that the analyst has created and refresh that data in Starburst perhaps using a materialized view.
- Using the SQL dataset definition, invest in building and maintaining a pipeline to create this dataset into a cloud data warehouse — the legacy data stack.
This choice will be based on not only the value likely to be accrued from answering this question, but also the cost of the related operationalization effort. If the value accrued from this new insight is not considerably more than the cost of building and maintaining the dataset in an expensive cloud data warehouse, then the organization should use Starburst, otherwise we might consider the cloud data warehouse approach.
Innovation management: Explore more freely with Starburst
Data-based organizations need technologies and a methodology that enable business analysts to drive innovation to make value-based, near real-time decisions on how we operationalize new insights to build new products and services. These are the processes and capabilities that Starburst provides, which are incredibly powerful to support the well-being of organizations in our digital economy and perhaps nurture a new generation of entrepreneurship.




