
My fascination with SQL query performance started quite some time ago and I contributed a paper on efficient processing of data warehousing during my graduate research. I always believed strongly that query performance is crucial for many reasons; the key ones are customer satisfaction, efficient use of energy and compute resources and low total cost of ownership.
When I first started working with Trino (formerly known as PrestoSQL) back in 2015, I was very happy to see that similar goals were shared by the community. Countless performance enhancements such as our Cost-Based Optimizer (CBO) were developed over the years to uphold our status as an extremely fast query engine for data anywhere. At Starburst, I am privileged to work with a number of talented engineers who, based on the valuable feedback from our customers, continue to take the speed of our SQL engine to the next level. Today I would like to review several important performance advancements exclusive to the Starburst Enterprise 360-e release that we announced last week.
Accelerated Parquet Reader
As many of you might be aware, ORC has been the best performing file format for Trino since its inception. Major enhancements to the ORC reader were introduced over two years ago. While the Parquet reader has become faster over time as well, we knew we could do even better. Given the growing popularity of Parquet, we wanted to bring our customers faster table reads while reducing the CPU utilization. Our chosen approach was to introduce a brand new Parquet reader in order to take full advantage of the potential optimizations.
The raw Parquet reader speed has improved significantly since the previous release as illustrated below:
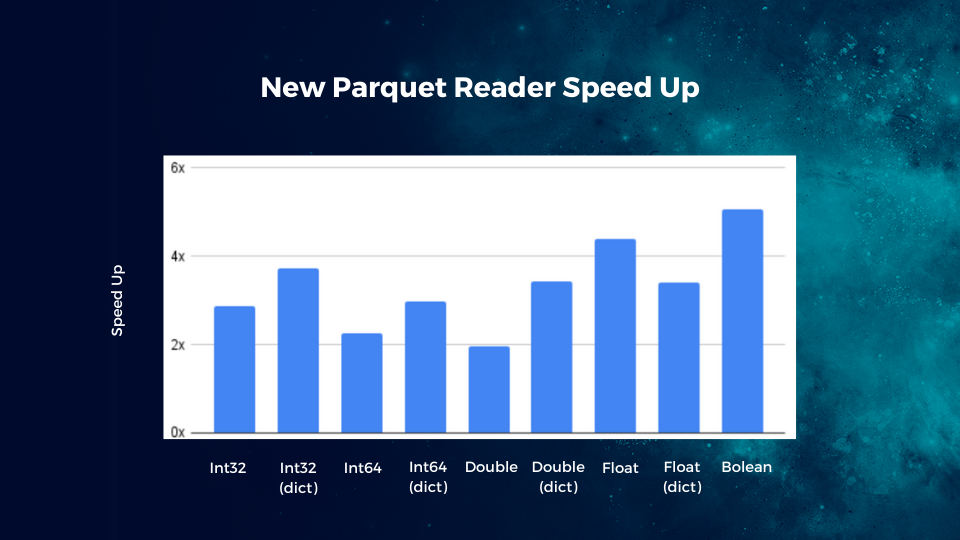
As a result of our optimizations, the overall query performance improved by an average of 20% and for some queries by as much as 30%.
Are we done yet? Not by a long shot… We have identified even more opportunities for improvement already. For example, while the focus so far has been mostly on speeding up access to integer columns, we will be accelerating string, decimals and other data types next.
Delta Lake Performance Optimization
Given that the Delta Lake table format leverages Parquet internally, all the gains discussed above are immediately applicable to queries over Delta Lake as well. But that’s just the beginning!
Delta Lake comes with basic table- and column-level statistics to help query optimizers pick fast query plans. However, it is missing one crucial statistic called the number of distinct values (NDV) for each column. Why are NDVs important? Basically, they allow the optimizer to estimate the amount of data to be processed at various stages of the query plan. For example, we want to estimate the number of rows that will pass through a filter expression and also estimate the number of rows to be produced as an output of a join operator. Without those two key estimates, our Optimizer has quite limited information to operate on when evaluating alternative join orderings and picking the most promising query plan.
To mitigate the lack of NDVs natively in Delta Lake, we’ve added support for a dedicated ANALYZE command to collect the necessary statistics when desired. When NDVs are gathered, the latency of most of the complex join queries improves dramatically. In our internal benchmarking, we observed an average improvement of 2x across 100+ queries with some of them achieving up to a 5x speedup. Quite a difference indeed! Please make sure to run ANALYZE for your Delta tables periodically to refresh NDVs in order to get the best query performance and more efficient use of resources.
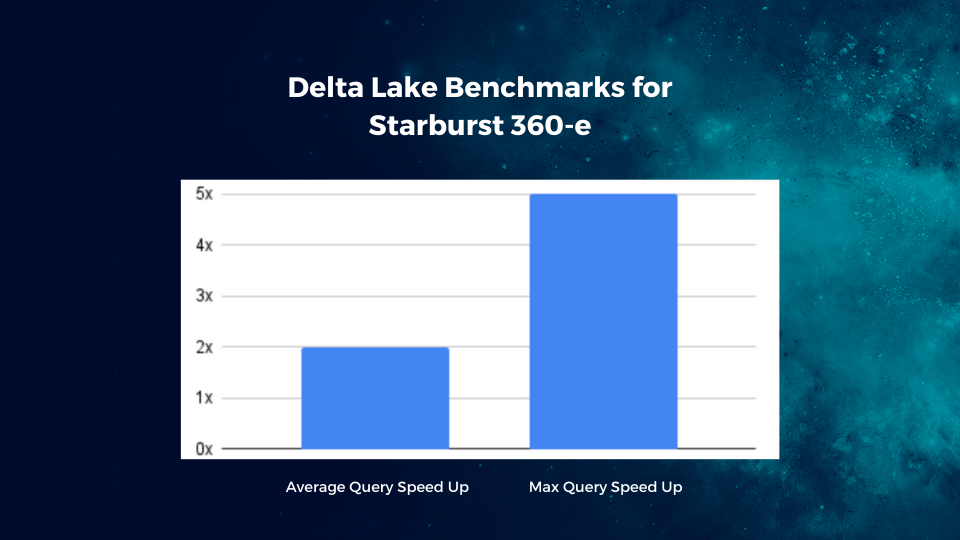
Obviously, there were a number of smaller optimizations along the way too and we are certainly planning to invest in additional enhancements in the near future.
Enhanced Dynamic Filtering
For some time now Starburst has been offering dynamic filtering which is an extremely useful technique to reduce the amount of data read-off storage. Such reduction minimizes network traffic inside and outside Starburst clusters and decreases compute power needed to execute queries. Before our 360-e release Starburst could already dynamically prune partitions and buckets as well as skip data segments inside ORC and Parquet files. What we are introducing now is additional dynamic filtering at the row level to further minimize the amount of data to be processed. This technique is especially powerful for selective filters on columns that are not used for partitioning, bucketing, or when the values do not appear in any clustered order naturally. For instance, in the case of a customer id column in the orders table, it is likely that the values are spread across the entire table in some semi-random order. If you look for orders for a small group of customers, your query will benefit greatly from eliminating most of the rows from the orders table right at the time of scanning it before redistributing rows for the join operation in the next stage.
The effect of this enhancement exceeded our expectations when the speed of certain benchmark queries improved by 4-6 times while other key resource metrics such as CPU, memory, and network decreased significantly as summarized below:

This dynamic filtering optimization is now available in our standard Data Lake connector (also known as the Hive connector) and will be coming shortly to other connectors including the Starburst Delta Lake Connector.
Conclusion: Query Engine Stack
As discussed above, Starburst is improving performance across the entire query engine stack. Starting with data access, through the query execution framework, and all the way to the query optimizer, we are achieving greater efficiency.
Let’s come back to the bigger picture for a moment. Performance matters when you want to optimize infrastructure cost, reduce time-to-insight or do more analytics in less time. All of those reasons are essential for most of our customers and therefore have high priority at Starburst.
Congratulations to our Performance and Lakehouse engineering teams for delivering amazing performance improvements in the recent Starburst 360-e release.
Ready to try Starburst? Download it here and let us know how we can optimize even further for your use case.




