


In the realm of data analytics, optimizing query performance proves to be a continuous and intricate challenge, especially on a data lake with high concurrency and extensive data volumes. Data engineers practice a multifaceted approach, using various tools and techniques to streamline query processes. Fine-tuning a flexible cache strategy is an elemental component of query execution and performance, allowing organizations to rapidly serve answers to queries through shared resource consumption.
Starburst Galaxy’s advanced features empower you to navigate complex analytical workloads seamlessly, ensuring fast, warehouse-like capabilities directly on the data lake and adaptability to changing data requirements. With new multilayer caching, plus built-in observability for timely interventions, Galaxy makes it easier to tailor and monitor your query optimization strategies, all within a single platform.
Introducing multilayer caching in Starburst Galaxy
Within Starburst Galaxy, caching is customizable to suit your specific requirements. In this blog, we will explore the three types of caching available in Starburst Galaxy.
- Warp Speed – Smart indexing and caching
- Result caching – now generally available
- Subquery caching – now in private preview
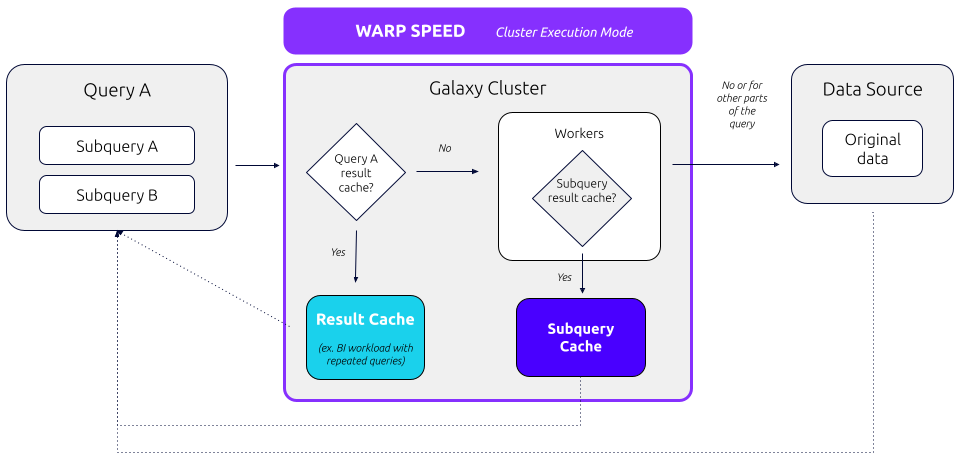
Warp Speed: Smart indexing and caching
At the core of our caching strategy is Warp Speed, our industry-leading indexing technology that autonomously identifies and caches the most used or relevant data based on usage patterns – without the need for manual partitioning strategies. This is particularly valuable for use cases involving multi-dimensional data that need to be filtered across many dimensions. A couple key examples are:
- Fraud /Anomaly detection
- IoT/Telemetry data
- Geospatial analytics
- Clickstream and Customer 360 analytics
- Logs analysis/Cyber Security
How does Warp Speed work?
Below is an example query demonstrating how Warp Speed analyzes and automatically creates the necessary index and cache elements to enhance performance.

As you can see, indexes are generated automatically, taking into account query patterns to reduce the need for full table scans. This proves particularly advantageous for workloads with numerous filtering predicates or selective filters in queries yielding a relatively small number of rows.
Behind the scenes, Warp Speed handles index and cache elements on the cluster’s SSDs in a proprietary format. Enabling Warp Speed results in the offloading of the most resource-intensive query operator, ScanFilterProject, to Warp Speed. This action substantially decreases the resources utilized by the operator and the entire query, resulting in quicker query execution times.
When to use Warp Speed
Warp Speed is especially useful for speeding up interactive workloads to meet SLAs and for querying more of your data lake at the same latency as current workloads. The acceleration is particularly advantageous when handling queries containing selective filters, as the indexing mechanism allows for direct access to the relevant rows, thereby avoiding the need to scan all or most of the data.
In practice, Warp Speed has proven to be most valuable in powering interactive data applications with large data volumes and high user concurrencies. It provides administrators with a compromise-free accelerated engine for optimizing price-performance at scale.
How do I use Warp Speed?
Warp Speed is configured at the cluster level and will index and cache elements automatically for you as soon as you start running queries. When configuring a cluster, simply select “accelerated” as the execution mode to get up and running with Warp Speed. It’s that easy!
Result caching is now generally available
Where Warp Speed aims to optimize query performance in workloads involving multi-dimensional filters, result cache improves query performance in scenarios with predominantly repeated queries by storing query results in memory. This layer significantly improves query runtime performance, resulting in a more efficient user experience with reduced wait times for results. Particularly for data applications and dashboard users, result caching streamlines the process by minimizing the necessity for query optimization before execution.
- Removing the need to re-run queries where recently computed results already exist
- Offloading redundant queries from the cluster
These advantages become particularly valuable when prioritizing performance, enhancing user experience while being mindful of resource consumption. The key lies in their diverse utility for improving performance across various use cases.
How does result caching work?
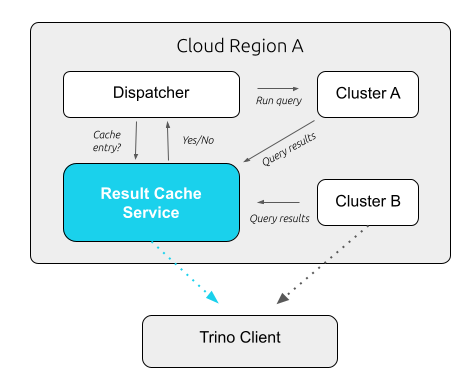
Think of the result cache as a quick-access storage system stored in memory within the Galaxy ecosystem. This enables users to efficiently share query results, especially when multiple users are accessing the same dashboard. In such a scenario, the result cache minimizes compute work, ensuring a faster time to insight for dashboard users.
As illustrated in the diagram, instances of the result caching service seamlessly integrate into each Trino Cluster region. These instances locally serve results using the Trino protocol while maintaining the robust security measures of the Trino cluster.
Users can activate result caching on a per-cluster basis, allowing them to fine-tune cache settings based on the unique characteristics of their workloads, providing additional flexibility and customization. Result caching is available for SELECT statements (up to 1 MB).
How do I use result caching?
Caching is enabled at the cluster level, allowing queries run on a cluster with caching enabled to leverage pre-computed results after their initial execution, regardless of the execution mode (Standard, Fault Tolerant, or Accelerated).
To enable caching, from the Clusters screen, for either new or existing Clusters, the cache toggle is located under Advanced Settings:

Note: the cache reuse period setting is adjustable from 5 minutes to 12 hours in one-minute increments. This setting allows queries to return cached results if generated within the time specified by the user. These settings can be customized based on preference and session configuration, with the default being 5 minutes.
You can learn more about result caching by checking out our docs.
Subquery caching is now in private preview
Subqueries often appear more than once in a single query and across multiple, non-identical queries. It’s often hard to manually optimize for those patterns. New subquery caching in Galaxy automatically identifies similar repeated subqueries and caches relevant partial results. By doing so, Galaxy avoids the need to recompute the results of identical subqueries multiple times, significantly reducing the computational overhead and improving overall query performance.
How does subquery caching work?
Galaxy stores the results of common subquery patterns in memory at the source stages of the query plan for subsequent reuse. The cache entries are very granular (split-level) and are later utilized across queries for data chunks that remain unaltered in the interim. Any new or modified data elements are processed from scratch and re-combined with what was cached earlier, ensuring that the final query results are always 100% accurate and up to date.
Let’s consider the following example. The first query computes two aggregations over a single table. While this query does not contain any subqueries, we will keep the partial results for potential reuse.

When the second query comes, we don’t need to recompute the two highlighted subqueries from scratch since they contain exactly the same aggregations present in the previous query.
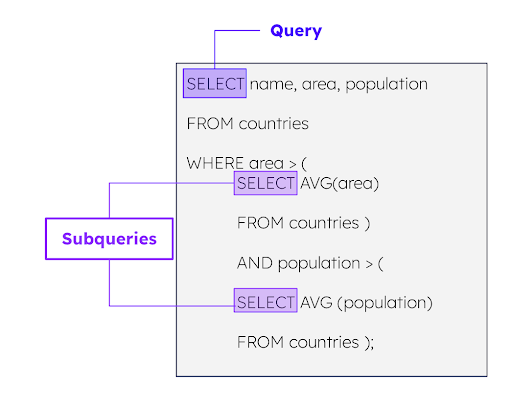
Obviously one could run the queries in different order and obtain the similar effect.
How do I use Subquery Caching?
Subquery caching is currently in private preview. If you are interested in being a part of the private preview and learning more about our future caching strategies, apply here.
What’s next
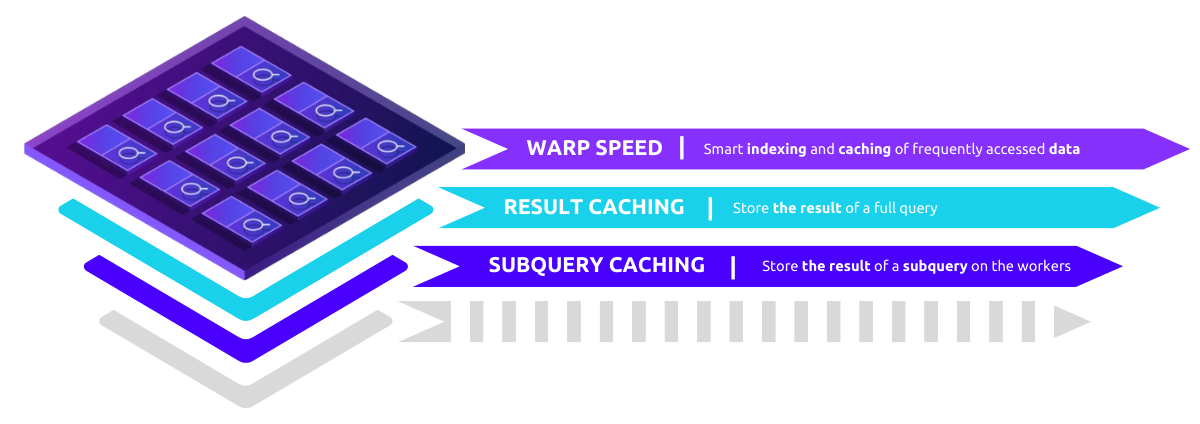
As data volumes and user demands increase, there’s a growing need for adaptive and intelligent optimization strategies. Starburst Galaxy’s multilayer caching approach, including Warp Speed, result caching, and subquery caching, marks just the starting point of our caching journey.
Want to learn more about what we’re working on? Check out our private preview programs or simply get started with your free Galaxy account.




