
In this post, we discuss the difference between a data lake and data warehouse and how Starburst helps with both.
Data lake vs data warehouse
Data warehouses marked an initial attempt to improve analytics at scale. Vendors provide on-premises solutions that combine storage and compute in an appliance business model. These systems store structured data in a predefined schema, making warehouses performant and reliable. However, data warehouses are inflexible since their schema cannot change, and they can only store structured data. In addition, vendor lock-in makes scaling expansive.
Data lakes decouple storage and compute. Especially when implemented in the cloud, these solutions can store vast amounts of structured, semi-structured, and unstructured data. Companies can take advantage of low-cost cloud storage to create a more affordable and scalable repository. However, data lakes rarely came with advanced analytics capabilities, forcing companies to develop additional data warehouses to support their big data initiatives.
Data lake with object storage
A data lake is a storage repository that can store a vast amount of raw data in its native format (such as structured, semi-structured, or unstructured) until it is needed. What’s great about data lakes is that you can store data without having to first structure it, which is a big advantage when dealing with large volumes of diverse data.
In a data lake, object storage is a common choice for storing large volumes of unstructured or semi-structured data. Object storage systems include: Amazon S3, Google Cloud Storage, or Azure Blob Storage.
Object storage serves as the foundational layer where raw data in various formats is stored and later retrieved for processing and analytics. As for processing and data analytics, organizations often use tools like Apache Spark or Trino to connect to their data lake.
Can a data lake replace a data warehouse?
A data warehouse is used for reporting. Data stored in a warehouse is cleaned, structured, and processed. Data warehouses are primarily used by business professionals who need structured data for standard reporting. Examples of data warehouses include Oracle, Snowflake, and IBM DB2.
Today, data lakes often coexist with data warehouses, where data warehouses are often built on top of data lakes. The most common implementation of this is using S3 as the data lake and Redshift as the data warehouse.
What is a data catalog in a data warehouse and data lake?
How both data warehouses and data lakes use their data catalogs are different. In a data warehouse architecture, the catalog controls how data is loaded. This is why warehouses are considered less flexible but faster because data gets a structure first, then it is written in proprietary optimized formats.
In a data lake, the catalog defines where existing data can be found and in what format (which is typically an open source format). Data lakes have traditionally been thought of as flexible and slower because data gets written in any format and then structured later.
Related reading: How data and schema interact with a data lake and data warehouse
Do data lakes use ETL?
Unlike data warehousing, a data lake holds a vast amount—terabytes and petabytes—of data in its native format. Once the data becomes available in the lake, the architecture gets extended with elaborate transformation pipelines to model the higher value data and store it in lakeshore marts. Essentially, we moved from ETL to ELT processing.
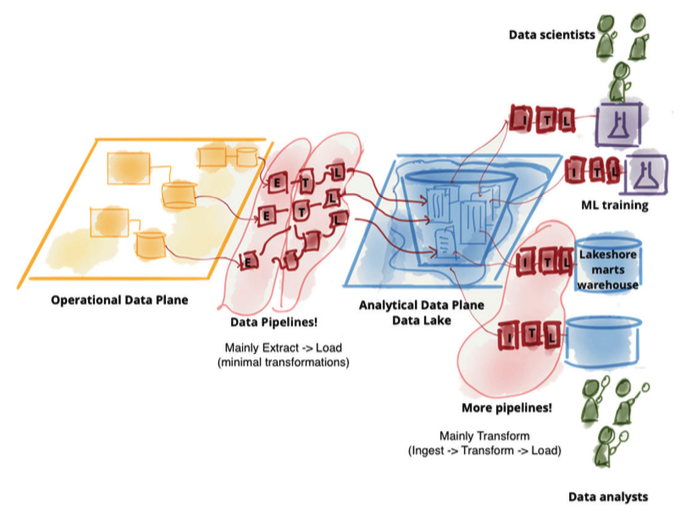
Does AWS have data lakes?
Data lakes run on AWS. Many organizations use Amazon S3 to build data lakes because of its durability, availability, scalability, security, compliance, and audit capabilities. Then query data from their data lake in Amazon S3 using your favorite SQL-based tool, such as Trino.
Why use a data lake instead of a database?
Data lakes are designed to store massive amounts of data. They can handle petabytes or exabytes of data, including unstructured data like text, images, and video, which traditional databases are not typically designed to handle efficiently.
How Starburst helps with both data warehouses and data lakes
“The data warehouse and data lake space is constantly evolving, and our enterprise focus means we have to support customer requirements across different platforms. Starburst gives us the ability to move quickly to support ever-changing use cases within complex enterprise environments.” — David Schulman, Head of Partner Marketing, Domino Data Lab
“We moved from a monolithic Snowflake approach to a decentralized approach with Starburst and Iceberg. Now we can skip the data warehouse step completely, and complete analytics on the data right where it sits.” – Lutz Künneke, Director of Engineering, BestSecret
“The implementation of Starburst on the data lake allows analysts and data scientists quick and simple access to data that exists in the organization for business value and insights. ETL processes that took many months and at high costs have become extremely fast and accessible to analysts at negligible costs.” — Shlomi Cohen, EVP, Head of Business Data and Analytics, Bank Hapoalim
What are some next steps you can take?
Below are three ways you can continue your journey to accelerate data access at your company
- 1
- 2
Automate the Icehouse: Our fully-managed open lakehouse platform
- 3
Follow us on YouTube, LinkedIn, and X(Twitter).




