The fastest path from Hadoop
to data lakehouse
Data companies build their Icehouse with Starburst






Your data architecture is unique to your specific business, governance, and security requirements. Data may continue to reside on-premises, in hybrid, or cloud centric data architectures and your lakehouse platform should support your requirements. With Starburst, you gain greater flexibility in how you modernize your Hadoop ecosystem while benefiting from an open data lakehouse.


Modernization paths
10x faster queries on data that will stay on-premises in HDFS by upgrading Hive/Impala with Starbursts enhanced MPP SQL query engine built using OS Trino. Also gain 10x more access to data across the enterprise for a more integrated data estate. Compare engines.
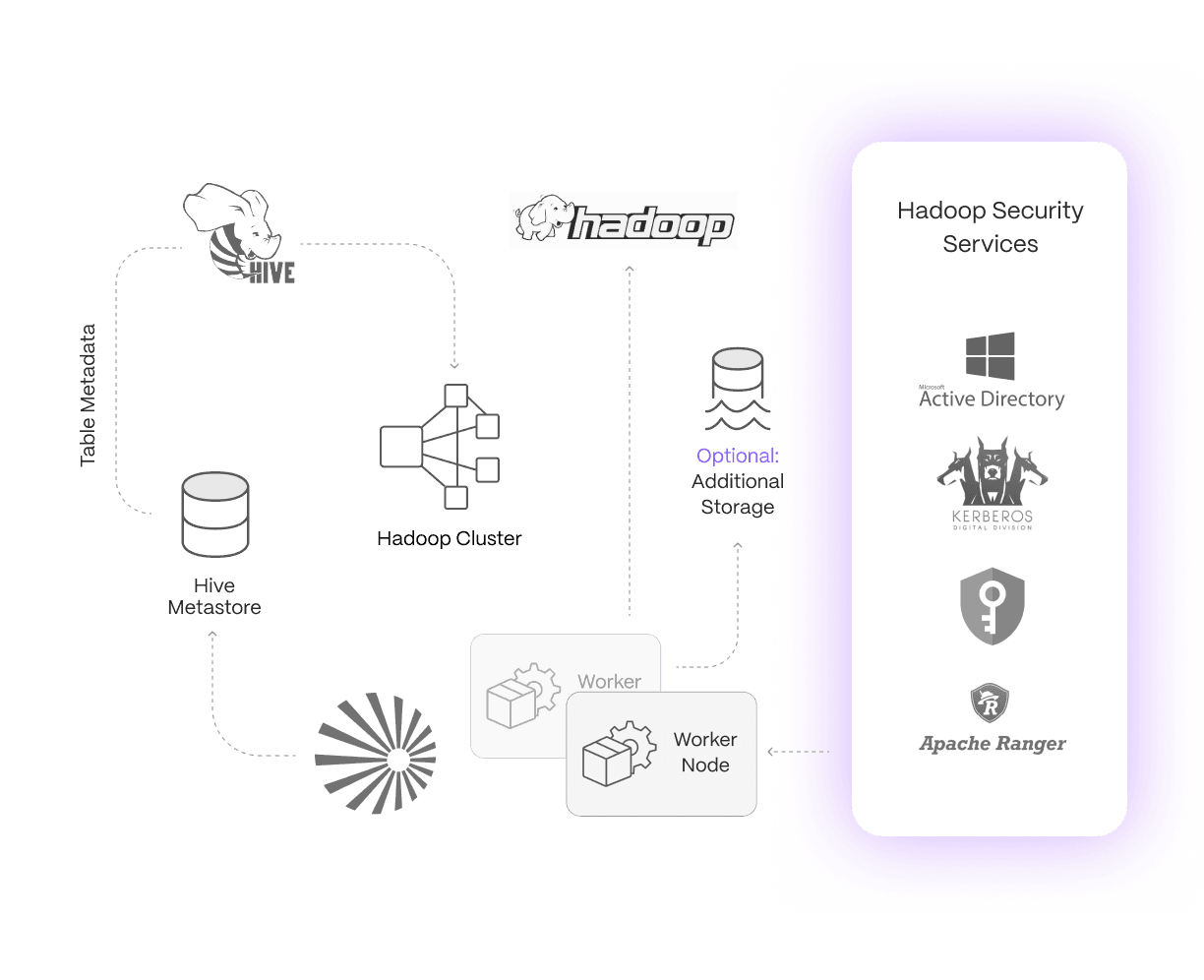
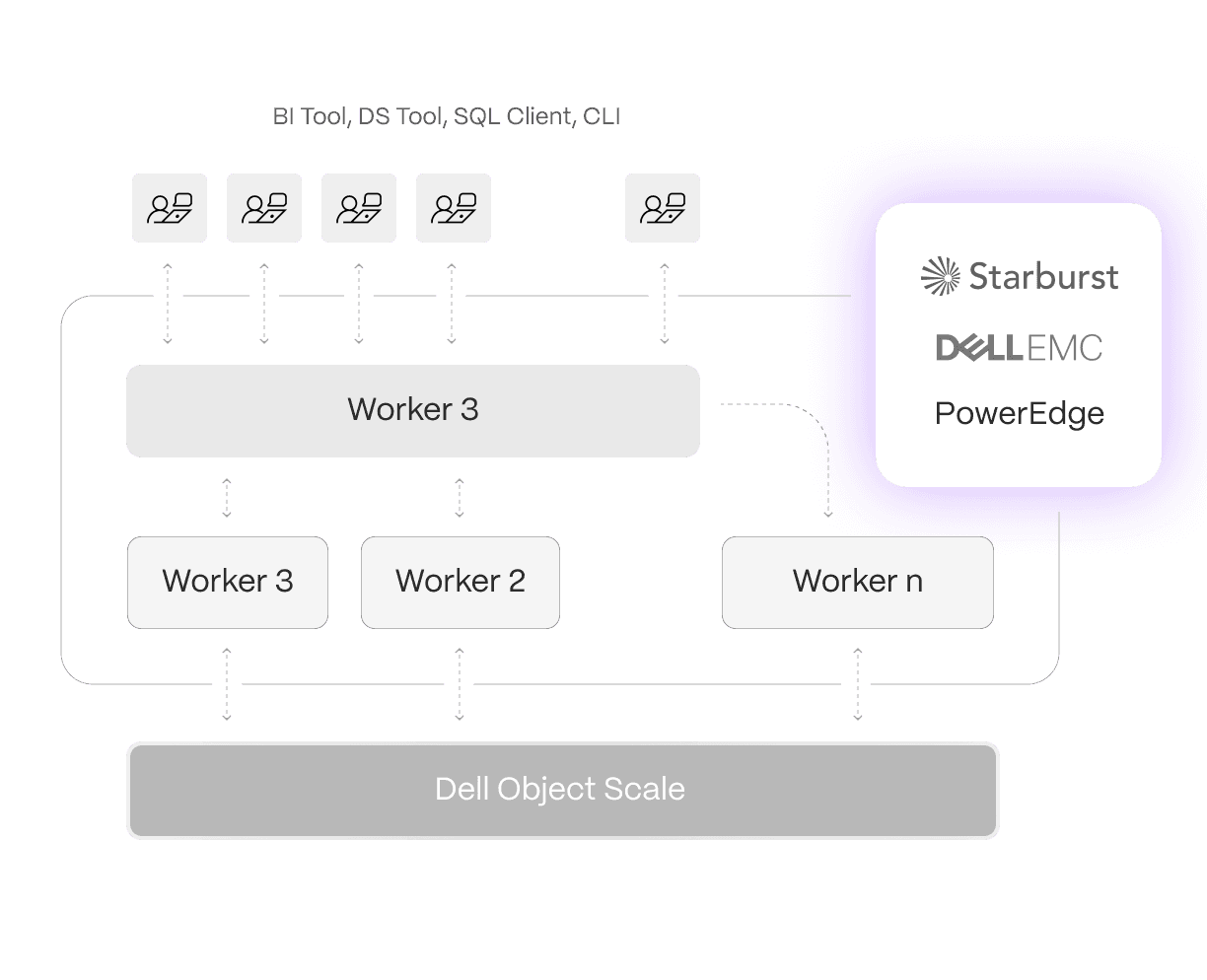
Upgrade from Hadoop to the Dell Data Analytics Engine powered by Starburst to gain more powerful and efficient on-premises compute, storage, and analytics while connecting to data in AWS S3, ADLS, GCS, and many more sources. Learn more.
Build an open and interoperable data lakehouse by migrating Hive to Iceberg to support cross-cloud and cross-region price-performant analytics at petabyte scale while democratizing secure data sharing with a single point of access and governance. Learn more.

Why an open data lakehouse?
Hadoop comes with many challenges, such as high maintenance costs, complex administration, scalability and nosey neighbor issues, and a lack of cloud-native features. An open data lakehouse overcomes the challenges of Hadoop to provide a cost-effective, performant, and future proof data architecture that is built on an open foundation.

Why Starburst?

Price-performant analytics at petabyte scale
Both Starburst Enterprise (software) and Galaxy (SaaS) are powered by enhanced open source Trino and designed for analyzing large and complex data sets in and around your data lake – at petabyte scale.
Power internet-scale SQL workloads with enhanced Trino – the engine built to replace Hive
Accelerate interactive queries 40%+ with Warp Speed
Run long-running, memory intensive workloads without the fear of query failure with enhanced fault-tolerant execution

Flexible and secure modernization with a simple user experience
Starburst makes it easy to discover, govern, analyze, and share data that enables the management of all your data assets through an easy-to-use interface.
Modernize based on the unique requirements of your modernization strategy
Secure data based on any input – where it lives, how it is structured, what it contains, or which teams it is relevant to
Purpose-built data products streamline secure sharing and collaboration

Single point of access and governance
Every data store is a first-class entity in Starburst. Use the architecture that meets your needs today and easily evolve it for tomorrow.
Connect to 50+ data sources and manage access through a single-entry point
Optimized for Apache Iceberg and works with all modern table and file formats, including Delta Lake, Apache Hudi, and Apache Hive
Analyze your data cross-region and cross-cloud from a single query
Value across industries




5 considerations for a successful modernization
Embarking on a modernization journey requires a strategic approach to ensure your systems are ready for the future. From evaluating your current environment to selecting the right cloud platform, designing robust architecture, and executing a seamless migration, every step must be carefully planned and executed.
Evaluate current environment
- Identify what data is staying on-premises and what is moving to the cloud
- Analyze data specifics, workflows, dependencies, and desired outcomes to define project scope and objectives
- Clearly document the desired end state
Select cloud platform
- Compare cloud options based on features, compatibility, and costs
- Match these with migration goals to identify the optimal cloud solution, potentially spanning multiple platforms
Design cloud architecture
- Map out storage, compute, and analytics layers
- Choose scalable storage (e.g., Azure Data Lake, Amazon S3), compute service (Trino), analytics tools, and account for security, governance, and observability
Plan data migration
- Prioritize batch migration over simultaneous transfer for efficiency
- Minimize disruption, monitor the process, and ensure business continuity by maintaining data federations between legacy and new system
- Be deliberate about which use cases to migrate first, start with low complexity to build early wins and learnings
Agile migration execution
- Prepare data by cleansing, transforming, and validating it
- Choose migration tools like Azure Copy, AWS Transfer, or BigQuery Data Transfer, and ensure incremental data movement for accuracy
- Consider managed options or manual scripts
“Gartner clients have described plans to replace broad, complex suites of jobs running against large, optimized data warehouses by “moving it to Hadoop.” Not surprisingly, many of these projects have not succeeded.”
Merv Adrian and Rick Greenwald

Explore Modernization resources







Start for Free with Starburst
Up to $500 in usage credits included

Discover
Easily search across data sources and clouds to find the data you need.

Govern
Streamline data governance with built-in RBAC and ABAC.

Analyze
Run internet-scale workloads with the power of Trino.
Fast
Accelerate queries with smart indexing and caching technologies like Warp Speed.
More Deployment Options
